1.语言详解--类型
1.1 变量
变量(variable)表示没有固定值且可以改变的数(数学定义),也可以说是一段或者多段用来存储数据的内存。(计算机系统定义)
作为静态类型语言,go变量总是有固定的数据类型,类型决定了变量内存的长度和存储格式,可以改变变量值(类型转换或指针操作),无法改变类型。
定义
关键字var用于定义变量,类型放在变量名后。运行时内存分配操作会确保变量自动初始化为二进制零值(zero value),避免出现不可控行为。 如显式提供初始化值,可省略变量类型,有编译器推断。
``
var x int //自动初始化为0
var y = false //自动推断为bool类型
可一次定义多个变量,包括用不同初始值定义不同类型
``
var x, y int //相同类型的多个变量
var a, s = 100, "abc" //不同类型的初始化值
按照编程习惯,建议以组的方式整理多行变量定义,即用大括号美观一点。
``
var {
x, y int
a, s =100, "abc"
}
简短模式(short variable declaration)
除var关键词外,还能使用如下模式
``
func main(){
x := 100
a, s :=1, "abc"
}
简短模式限制
1. 定义变量,同时显式初始化
2. 不能提供数据类型
3. 只能用于函数内部
简短模式不一定总是重新定义变量,也可能是部分退化的赋值操作。 退化赋值的前提条件是 最少有一个新变量被定义且必须是同一作用域。
```
func main(){
x := 100
println(&x)
x := 200 //错误:no new variable on left side of :=
println(&x, x)
}
```
输出: 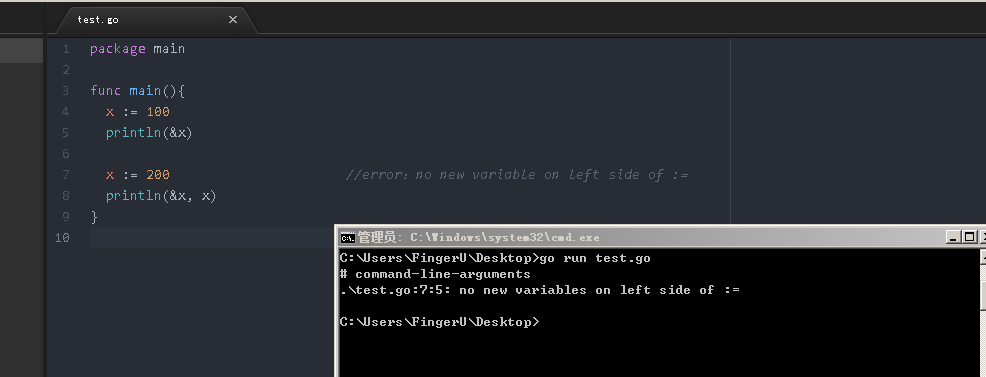
```
func main(){
x := 100
println(&x,x)
{x, y := 200, 300 //不同作用域,全部hi新变量定义
println(&x, x, y)
}
}
```
在处理函数错误返回值时,退化赋值允许我们重复使用err变量
```
package main
import {
"log"
"os"
}
func main() {
f, err := os.open("/dev/radom")
...
buf := make([]byte, 1024)
n, err := f.read(buf) //err退化赋值,n新定义
}
```
多变量赋值
先计算出所有右值,再依次完成赋值操作。
``
func main(){
x, y := 1,2
x, y = y+3, x+2
println(x, y)
}
输出: 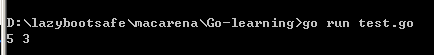
5 3
#### tips:赋值操作,必须确保左右值类型相同
未使用错误
go语言的神奇之处,编译器讲未使用的局部变量当做错误,虽说知道它的初衷是好的,有助于培养良好的编程习惯。
1.2 命名
每个程序猿都会有自己变量命名习惯,但是还是建议标准化命名。
空标识符
和python类似,go也有一个名为 _ 的特殊成员(blank identifier)。通常作为忽略占位符使用,可做表达式,无法读取内容。
```
import "strconv"
func main() {
x, _ := strconv.Atoi("12") // 忽略atoi的err返回值
println(x)
}
```
空标识符可用于临时规避编译器对未使用变量和导入包的错误检查。但他是预置成员,不能重新定义。
1.3 常量
常量就是指运行时不变的值,通常是一些字面量。使用常量就可用一个易于阅读的标识符号来代替“魔法数字”, 也使得在调整常量值时,无需修改所有引用代码。
- 常量值必须是编译器可确定的字符,字符串,数字或者布尔型。可指定常量类型,或有编译器通过初始化值推断,和之前一样。
- 可在函数代码块中定义常量,不曾使用的常量不会引发编译错误
- 显式指定类型,确保常量左右值类型一致,可做显式转换。右值不能超出常量类型取值范围,否则会溢出。
- 常量值也可以是某些编译器计算出结果的表达式,如 unsafesizeoflencap等
- 在常量组中如不能指定类型和初始化值,则与上一行非空常量右值(表达式文本)相同。
例子:
```
import "fmt"
func main() {
const(
x uint16 = 120
y //与上一行x类型,右值相同
s = "abc"
z //与s的烈性,右值相同
)
fmt.println("%T, %v\n", y, y)
fmt.println("%T, %v\n", z, z)
}
```
输出:
uint16, 120<br> string, abc
枚举
go语言没有明确意义上的enum定义,但是可借助iota标识符实现一组自增常量值来实现枚举类型。
``
const(
x = iota //0
y //1
z //2
)
- 自增作用范围是常量值,可在多个常量定义中使用多个iota,各自有单独技术,只需确保组中每行常量的列数量相同即可。
- 如中断iota自增,必须显式恢复。且后续自增值按行序递增,而非c enum 那般按上一取值递增。
- 自增默认数据类型为int, 可显式指定类型。
- 在实际编码中,建议用自定义类型实现用途明确的枚举类型。
展开
不同于变量在运行期分配存储内存,常量通常会被编译器在预处理阶段直接展开,作为指令数据使用。
```
const y = 0x200
func main() {
println(y)
}
```
数字常量不会分配存储空间,无需像变量那么通过内存寻址来取值,所以也不会获得地址。
1.4 基本类型
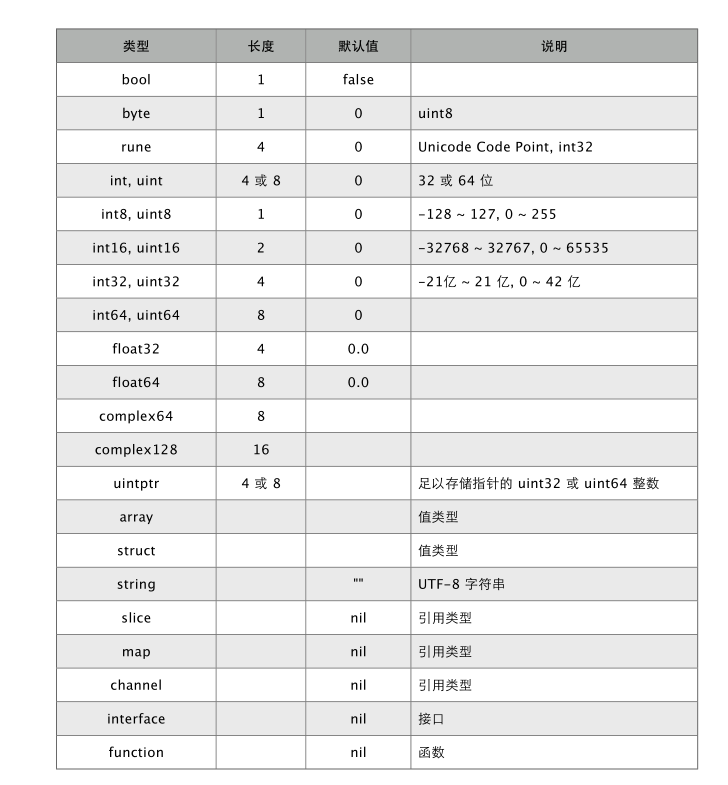
- 支持八进制、十六进制以及科学计算书法。标准库math定义了各数字类型的取值范围。
- 标准库strconv可在不同进制(字符串)间转换。
- 使用浮点数,需注意小数位的有效精度
别名
在官方的规范中,专门提到有两个别名:
``
byte alis for uint8
tune alis for int32
别名类型无需转换,可直接赋值。
1.5 引用类型
- 引用类型(reference type) 特指slice map channel 这三种预定义类型
- 他们有浮渣的存储结构,除了分配内存外,还需要初始化相关属性。
- 内置函数 new 计算类型⼤大⼩小,为其分配零值内存,返回指针。而 make会被编译器翻译 成具体的创建函数,由其分配内存和初始化成员结构,返回对象而非指针。
1.6 类型转换
除常量,别名类型以及未命名类型外,go强制要求使用显式类型转换,加上不支持操作符重载。
- 同样不能将非bool类型结果当做true or false 使用。
语法歧义
如果转换的目标是指针,单向通道或没有返回值的函数类型,那么必须使用括号,以避免语法分解错误。
``
func main() {
x := 100
p := int(&x) //error : cannot convert &x (type int) to type int32
// invalid indirect of int(&x) (type int)
}
正确的做法是用括号,让编译器 讲\*int解析为指针类型
``
Point(p) // 相当于 (Point(p))
(*Point)(p)
<-chan int(c) // 相当于 <-(chan int(c))
(<-chan int)(c)
1.7 自定义类型
可将类型分为命名和未命名两⼤大类。命名类型包括 bool、int、string 等,而array、 slice、map 等和具体元素类型、长度等有关,属于未命名类型。
- 具有相同声明的未命名类型被视为同一类型。
- 具有相同基类型的指针。
- 具有相同元素类型和⻓长度的 array。
- 具有相同元素类型的 slice。
- 具有相同键值类型的 map。
- 具有相同元素类型和传送⽅方向的 channel。
- 具有相同字段序列 (字段名、类型、标签、顺序) 的匿名 struct。
- 签名相同 (参数和返回值,不包括参数名称) 的 function。
- 方法集相同 (方法名、方法签名相同,和次序无关) 的 interface。
未命名类型转换规则
- 所属类型相同
- 基础类型相同,且其中一个是未命名类型
- 数据类型相同,讲双向通道赋值给单向通道,且其中一个为未命名类型
- 将默认值nil赋值给切片 字典 通道 指针 函数 接口
- 对象实现了目标接口
``
x := 1234
var b bigint = bigint(x) // 必须显式转换,除⾮非是常量。
var b2 int64 = int64(b)
var s myslice = []int{1, 2, 3} // 未命名类型,隐式转换。
var s2 []int = s
2.语言详解--表达式
2.1 保留字
go语言仅有25个保留字(keyword),保留关键词不能用用作常量 变量 函数名以及结构字段等标识符。
``
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
每行五个,比较好记。
2.2 运算符
> 硬件的方向是物理,软件的方向是数学。----窃·格拉瓦
全部运算符以及分隔符列表:
``
+ & += &= && == != ( )
- | -= |= || < <= [ ]
^ = ^= <- > >= { }
/ << /= <<= ++ = := , ;
% >> %= >>= -- ! ... . :
&^ &^=
优先级
一元运算符优先级最高,二元则分成五个级别,从高到低分别是:
``
优先级 运算符 说明
------------+---------------------------------------------+----------------------------
high * / & << >> & &^
+ - |? ^
== != < <= < >=
<- channel
&&
low ||
相同优先级的二元运算符,从左往右。
二元运算符
- 除唯一操作外,操作数类型必须相同。如果其中一个是无显式类型声明的常量,那么该常量操作数会自动转型。
- 位移右操作数必须是无符号证书,或可以转换的无显式类型常量
- 如果是非常量位移表达式,优先将无显式类型的常量左操作数转型
位运算符
二进制位运算符比较特别的就是 bit clear,在其他于语言里很少见到。
``
-----------+----------------+-------+-----------------------------
AND 按位于:都为1 a&b 0101&0011 = 0001
OR 按位或 至少一个1 a|b 0101|0011 = 0111
XOR 按位异或 只有一个1 a^b 0101^0011 = 0110
NOT 按位取反 一元 ^a ^0111 = 1000
AND NOT 按位清除 bit clear a&^b 0110&^ 1011 = 0100
LEFT SHIFT 位左移 a<<2 0001<<3=1000
RIGHT SHIFT 位右移 a>>2 1010>>2 = 0010
自增
自增自减不再是运算符只能作为独立语句,不能用于表达式。
指针
内存地址是内存中每个字节单元的唯一编号,而指针则是一个实体。指针会分配内存空间,相当于一个专门用来保存内存地址的整型变量。
- 取址运算符 & 用于获取对象的地址
- 指针运算符 用于间接引用目标对象
- 二级指针 T 如包含报名则写成 package.T
- 并非所有对象都能进行取地址操作,但变量总是能正确返回(addressable)指针运算符为左值的时候,可更新目标对象状态; 而为右值时则是为了获取目标状态。
- 指针类型支持相等运算符,但不能做加减法运行和类型转换
``
x := 1234
p := &x
p++ // Error: invalid operation: p += 1 (mismatched types *int and int)
- 指针没有专门指向成员的 _>运算符,统一使用 . 选择表达式
零长度(zero-size)对象的地址是否相等和具体的实现版本有关。
2.3 初始化
对复合对象类型(数组 切片 字典 结构体 )变量初始化时,有一些语法限制:
- 初始化表达式必须含类型标签
- 左花括号必须在类型尾部,不能另起一行
- 多个成员初始值以逗号分隔
- 允许多行,但每行必须以逗号或者右花括号结束
``
// var a struct { x int } = { 100 } // syntax error
// var b []int = { 1, 2, 3 } // syntax error
// c := struct {x int; y string} // syntax error: unexpected semicolon or newline
// {
// }
var a = struct{ x int }{100}
var b = []int{1, 2, 3}
``
a := []int{
1,
2 // Error: need trailing comma before newline in composite literal
}
a := []int{
1,
2, // ok
}
b := []int{
1,
2 } // ok
2.4 流控制
if ...else
- 可省略条件表达式括号
- 支持初始化语句,可定义代码块局部变量
- 代码块左大括号必须在条件表达式尾部
- 条件表达式必须是布尔类型
``
x := 0
// if x > 10 // Error: missing condition in if statement
// {
// }
if n := "abc"; x > 0 { // 初始化语句未必就是定义变量,⽐比如 println("init") 也是可以的。
println(n[2])
} else if x < 0 { // 注意 else if 和 else 左⼤大括号位置。
println(n[1])
} else {
println(n[0])
}
switch
```
x := []int{1, 2, 3}
i := 2
switch i {
case x[1]:
println("a")
case 1, 3:
println("b")
default:
println("c")
}
```
输出: a
如需要继续下一分支,可使用 fallthrough,但不再判断条件。
``
x := 10
switch x {
case 10:
println("a")
fallthrough
case 0:
println("b")
}
输出:
``
a
b
省略条件表达式,可当 if...else if...else 使用。
``
switch {
case x[1] > 0:
println("a")
case x[1] < 0:
println("b")
default:
println("c")
}
switch i := x[2]; { // 带初始化语句
case i > 0:
println("a")
case i < 0:
println("b")
default:
println("c")
}
for
仅有for一种循环语句,但是常用方式都能支持。
``
s := "abc"
for i, n := 0, len(s); i < n; i++ { // 常见的 for 循环,支持初始化语句。
println(s[i])
}
n := len(s)
for n > 0 { // 替代 while (n > 0) {}
println(s[n]) // 替代 for (; n > 0;) {}
n--
}
for { // 替代 while (true) {}
println(s) // 替代 for (;;) {}
}
- 初始化语句仅被执行一次。条件表达式中如有函数调用,需确认是否会有重复执行。可能会被编译器优化掉。
- 可用for range完成数据迭代,支持字符串,数组,数组指针,切片,字典,通道类型,返回索引,键值数据。
``
data type 1st value 2nd value
-------------+----------------+-----------------------+-------------
string index s[index] unicode,rune
array/alice index v[index]
map key value
channel element
code:
```
func main() {
data := [3]string{"a", "b", "c"}
for i, s := range data {
println(i, s)
}
}
```
输出:
``
0 a
1 b
2 c
#### 没有相关接口显式自定义类型迭代,除非基础类型是上述类型之一
- 允许返回单值,或用 _ 忽略 code:
```
func main() {
data :=[3]string{"a", "b", "c"}
for i := range data{ //只返回单值1st value
println(i, data[i])
}
for _, s := range data { //忽略1st value
println(s)
}
for range data{ //仅迭代,不反悔,可用来执行清空channel等操作。
}
}
```
- 无论普通for循环,还是range迭代,其定义的局部变量都会重复使用
code:
```
func main() {
data := [3]string{"a", "b", "c"}
for i, s =: range data {
println(&i, &s)
}
}
```
- 注意 range 会复制目标数据,收直接影响的书数字,可改用数组指针或切片类型。
- 相关数据类型中,字符串切片基本结构是个很小的结构体,而字典 通道本身是真真邓庄,赋值成本都很小,无需专门优化。
- 如果range 目标表达式是函数调用,也仅被执行一次。
- 建议嵌套循环不要超过两层
goto, continue , break
- 使用goto前,需先定义标签。标签区分大小写,且未使用的标签会引发编译器的错误。 code:
```
func main() {
start:
for i := ; i < 3, i++ { //error:label start defined and not used
println(i)
if i > 1 {
goto exit
}
}
exit:
println("exit.")
}
```
- 不能跳转到其他函数,或内层代码执行
code:
```
func test() {
test:
println("test")
println("test exit.")
}
func main() {
for i := 0; i < 3; i++ {
loop:
println(i)
}
goto test //error:label test not defined
goto loop //error: goto loop jumps into block
}
```
- 和goto定点挑战不同, break、continue用于终端代码块执行。
- break 用于switch for select 语句,终止整个语句块的执行。
- continue 仅用于for循环,终止后续逻辑,立即进入下一轮循环。 code:
```
func main () {
for i := 0; i < 3; i++ {
continue //立即进入下一轮循环
}
if i > 5 {
break //立即终止整个for循环
}
println(i)
}
```
输出:
``
1
3
5
- 配合标签,break和continue可在多层嵌套中指定目标层级。
3.语言详解--函数
3.1 定义
函数是结构化编程的最小模块单元。他将复杂的算法过程分解为若干个小任务,隐藏相关细节,使得程序结构更加清晰。函数被设计成相对独立,通过接受输入参数完成一段算法指令,输出货存储相关结果。关键字func 用于定义函数,go中的函数不太方便的限制,也借鉴了动态语言的某些优点。
- <font color=red>无须前置声明</font>
- <font color=red>不支持命名嵌套定义(nested)</font>
- <font color=red>不支持同名函数重载(overload)</font>
- <font color=red>不支持默认参数</font>
- <font color=red>支持不定长便参</font>
- <font color=red>支持多返回值</font>
- <font color=red>支持命名返回值</font>
- <font color=red>支持匿名函数和闭包</font>
> <font color=red><b>不支持左花括号另起一行</b></font>
- 函数属于第一类对象,具备相同签名(参数及返回值列表)的视作同一类型。 code:
```
func hello() {
println("hello,sir!")
}
func exec(f func()){
f()
}
func main(){
f := hello
exec(f)
}
```
- 第一类对象(first-class object)只可在运行期创建,可用做函数参数或者返回值,可存入变量的实体。最常见的用法就是匿名函数。
- 从代码维护的角度来说,使用命名类型更加方便
code:
```
// 定义函数类型
type formatFunc(string, ...interface{}) (string, error)
//如不使用命名类型,这个参数签名会长的爆炸。
type format(f formatFunc, s string, a...interface{}) (string, error) {
return f(s, a...)
}
```
- 函数只能判断是否为nil 不支持其他比较操作。
code:
``
func a...
func b...
println(a == nil)
println(a == b) // 无效操作
- 从函数返回局部变量指针是安全的,编译器会通过逃逸分析(escape analysis)来决定是否在堆上分配内存。
code:
```
func test() *int {
a := 0x100
return &a
}
func main() {
var a *int =test()
println(a, &a)
}
```
输出:(省略)
```
$go build -gcflags "-l -m" //禁用函数内联,输出优化信息
....
....
$go tool objdump -s "main\.main" test //反汇编确认
......
......
```
- 函数内联(inline)对内存分配有一定的影响。如果上列中允许内联,那么就会直接在栈上分配内存。
- 当前编译器并未实现尾递归优化(tail-call optimization)尽管go执行栈的上限是gb规模,轻易不会出现堆栈溢出(Stack Overflow)醋五,但还是需要注意拷贝栈的赋值成本。
建议命名规则
这个就不用多说了
每个程序猿都有自己的规则。。
3.2 参数
go对参数的处理偏向保守,不支持有默认值的可选参数,不支持实参,调用时,必须按签名顺序传递指定类型和数量的实参,就算以 _ 命名的参数也不能忽略。
- 在参数列表中,相邻的同类型参数可合并
code:
```
func test(x, y int, s string, _ bool) *int {
return nil
}
func main() {
test(1, 2, "abc") // error : enough arguments in call to test
}
```
- 参数可视作函数局部变量,因此不能在相同层次定义同名变量。
code:
``
func add(x, y int) int {
x := 100 //error : no new variables on the left side of :=
var y int // error : y redeclared in this block
return x + y
}
- 形参是指函数定义中的参数,实参则是函数的调用时所传递的参数。形参类似函数局部变量,而实参则是函数外部对象,可以是常量 变量,表达式 或者函数等。
- 不管是指针,引用类型,还是其他的类型参数,都是值拷贝传递(pass-by-value)。区别无非是拷贝目标对象,还是拷贝指针而已。在函数调用前,回味形参和返回值分配内存空间,并将实参拷贝到形参内存。
code:
```
func test(x *int) {
fmt.printf("pointer: %p, target: %v\n", &x, x) //输出形参x的地址
}
func main() {
a := 0x100
p := &a
fmt.printf("pointer: %p, target: %v\n", &p, p) //输出实参p的地址
test(p)
}
```
从输出结果可以看出,尽管实参和形参都指向同一目标,但传递指针时依然被复制。
- 下面是一个指针参数导致实参变量被分配到堆上的简单实例,可对比传值参数的汇编代码,可看出具体的差别。
code:
```
func test(p *int) {
go func(){
println(p) //延长p的生命周期
}()
}
func main() {
x := 100
p := &x
test(p)
}
```
输出:
```
$ go build -gcflags "-m" //输出编译器优化策略
moved to heap :x
&x excapes to heap //逃逸
$ go tool objdump -s "main\.main" test
.........
CALL runtime.newobject(SB) //在堆上为x分配内存
```
- 要实现传出参数(out),通常建议使用返回值,也可以继续用二级指针。
code:
```
func test(p *int) {
x := 100
p = &x
}
func main() {
var p int
test(&p)
println(p)
}
```
输出:
100
- 如果函数参数过多,建议将其重构成一个复合结构类型,也算是变相实现可选参数和命名实参的功能。
code:
```
type serverOption struct {
address string
port int
path string
timeout time.Duration
log *log.Logger
}
func newOption() serverOption {
return &serverOption{
address:"0.0.0.0"
port: 8080,
path: "/var/test",
timeout: time.Second 5,
log: nil,
}
}
func server(option *serverOption) {}
func main() {
opt := newOption()
opt.port = 8085, //命名参数设置
server(opt)
}
```
- 将过多的参数独立成option struct,既便于拓展参数集,也方便通过newOption 函数设置默认配置。这也是代码复用的一种当时,避免处处调用时繁琐的参数配置。
变参
变参本质上就是切片slice。 只能有一个,且必须是最后一个,即列表尾部。
```
func test(s string, n ...int) string {
var x int
for _, i := range n {
x += i
}
return fmt.Sprintf(s, x)
}
func main() {
println(test("sum: %d", 1, 2, 3))
}
```
使用切片 slice 对象做变参时,必须展开。
``
func main() {
s := []int{1, 2, 3}
println(test("sum: %d", s...))
}
3.3 返回值
- 有返回值的函数,必须有明确的return终止语句。
``
func test(x int) int {
if x > 0 {
return 1
}else if x < 0 {
return -1
}
} // error: missing return at the end of function
- 除非有painc,或者无break的死循环,则无需return终止语句。
``
func test(x int) int {
for {
break
}
} //error : missing return at the end of function
- 借鉴自动态语言的多分返回值模式,函数得以返回更多状态,尤其是error模式。
```
import "error"
func div(x, y int) (int, error) {
if y == 0 {
return 0, error.New("division by xx")
}
return x / y, nil
}
```
- 稍有不便的是没有元祖(tuple)类型,也不能用数组,切片接受,但可用_忽略不想要的返回值。多返回值可用作其他函数调用实参,或当做结果直接返回。
- 多返回值可直接作为其他函数调用实参。<br>
```
func test() (int, int) {
return 1, 2
}
func add(x, y int) int {
return x + y
}
func sum(n ...int) int {
var x int
for _, i := range n {
x += i
}
return x
}
func main() {
println(add(test()))
println(sum(test()))
}
```
- 命名返回参数可看做与形参类似的局部变量,最后由 return 隐式返回。<br>
```
func add(x, y int) (z int) {
z = x + y
return
}
func main() {
println(add(1, 2))
}
```
- 命名返回参数可被同名局部变量遮蔽,此时需要显式返回。<br>
``
func add(x, y int) (z int) {
{ // 不能在一个级别,引发 "z redeclared in this block" 错误。
var z = x + y
// return // Error: z is shadowed during return
return z // 必须显式返回。
}
}
- 命名返回参数允许 defer 延迟调用通过闭包读取和修改。
```
func add(x, y int) (z int) {
defer func() {
z += 100
}()
z = x + y
return
}
func main() {
println(add(1, 2)) // 输出: 103
}
```
- 显式 return 返回前,会先修改命名返回参数。
```
func add(x, y int) (z int) {
defer func() {
println(z) // 输出: 203
}()
z = x + y
return z + 200 // 执⾏行顺序: (z = z + 200) -> (call defer) -> (ret)
}
func main() {
println(add(1, 2)) // 输出: 203
```
命名返回值
对返回值命名和简短变量定义一样。
```
func paging(sql string, index nil) (count int, pages int, err error) {
}
```
3.4 匿名函数
- 匿名函数是指没有定义名字符号的函数。除了没有名字外,匿名函数和普通函数完全相同。
- 最大的区别是我们可在函数内部定义匿名函数,形成类似嵌套效果。匿名函数可直接调用,保存到变量,作为参数或返回值。
- 匿名函数可赋值给变量,做为结构字段,或者在 channel 里传送。
```
// --- function variable ---
fn := func() { println("Hello, World!") }
fn()
// --- function collection ---
fns := [](func(x int) int){
func(x int) int { return x + 1 },
func(x int) int { return x + 2 },
}
println(fns[0](100))
// --- function as field ---
d := struct {
fn func() string
}{
fn: func() string { return "Hello, World!" },
}
println(d.fn())
// --- channel of function ---
fc := make(chan func() string, 2)
fc <- func() string { return "Hello, World!" }
println((<-fc)())
```
- 除了闭包因素外,匿名函数也是一种常见的重构手段,可将大函数分解成多个相对独立的匿名函数块,然后用相对简洁的调用完成逻辑流程,以实现框架和细节分离。
- 相比语句块,匿名函数的作用域被隔离(不使用闭包),不会引发外部污染,更加灵活。没有定义顺序先知,必要时刻抽离,便于实现干净清晰的代码层次。
- 闭包复制的是原对象指针,这就很容易解释延迟引用现象。
- 闭包(closure)是在其词法上下文中引用了自由变量的函数,或者说是函数和其引用的环境的组合体。
```
func test() func() {
x := 100
fmt.Printf("x (%p) = %d\n", &x, x)
return func() {
fmt.Printf("x (%p) = %d\n", &x, x)
}
}
func main() {
f := test()
f()
}
```
输出:
``
x (0x2101ef018) = 100
x (0x2101ef018) = 100
- 在汇编层面,test 实际返回的是 FuncVal 对象,其中包含了匿名函数地址、闭包对象指 针。当调用匿名函数时,只需以某个寄存器传递该对象即可。
- 通过输出指针,我们注意到闭包直接引用了原环境变量。分析汇编代码,返回值不仅是匿名函数还包括了引用的环境变量指针。
- 汇编代码和我们主题无关,这里就不贴上去了。。。
``
FuncVal { func_address, closure_var_pointer ... }
- 闭包通过指针引用缓解经变量,会导致生命周期延长,甚至会被分配到堆内存,所谓“延迟求值”的特征。
```
func test() []func() {
var s []func()
for i :=;i < 2; i++ {
s = append(s, func() {
println(&i, i)
)}
}
return s
}
func main() {
for _, f :=range test() {
f()
}
}
```
- 解决办法就是每次用不同的环境变量或传参复制,让各自闭包环境各不相同。
- 多个匿名函数引用统一环境变量,也会让事情变得更加复杂。任何的修改行为都会影响其他函数取值,在并发模式下可能需要做同步处理。
3.5 延迟调用
- 关键字 defer 用于注册延迟调用。这些调用直到 return 前才被执行,通常用于释放资源或错误处理。
``
func test() error {
f, err := os.Create("test.txt")
if err != nil { return err }
defer f.Close() // 注册调用,而不是注册函数。必须提供参数,哪怕为空。
f.WriteString("Hello, World!")
return nil
}
- 多个 defer 注册,按 FILO 次序执⾏行。哪怕函数或某个延迟调用发生错误,这些调用依旧会被执行。
```
func test(x int) {
defer println("a")
defer println("b")
defer func() {
println(100 / x) // div0 异常未被捕获,逐步往外传递,最终终止进程。
}()
defer println("c")
}
func main() {
test(0)
}
```
输出:
``
c
b
a
panic: runtime error: integer divide by zero
- 延迟调用参数在注册时求值或复制,可用指针或闭包 "延迟" 读取。
``
func test() {
x, y := 10, 20
defer func(i int) {
println("defer:", i, y) // y 闭包引用
}(x) // x 被复制
x += 10
y += 100
println("x =", x, "y =", y)
}
输出:
``
x = 20 y = 120
defer: 10 120
- 滥用 defer 可能会导致性能问题,尤其是在一个 "大循环" 里。
```
var lock sync.Mutex
func test() {
lock.Lock()
lock.Unlock()
}
func testdefer() {
lock.Lock()
defer lock.Unlock()
}
func BenchmarkTest(b *testing.B) {
for i := 0; i < b.N; i++ {
test()
}
}
func BenchmarkTestDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
testdefer()
}
}
```
输出:
``
BenchmarkTest? 50000000 43 ns/op
BenchmarkTestDefer 20000000 128 ns/op
3.6 错误处理
- 没有结构化异常,使用 panic 抛出错误,recover 捕获错误。
``
func test() {
defer func() {
if err := recover(); err != nil {
println(err.(string)) // 将 interface{} 转型为具体类型。
}
}()
panic("panic error!")
}
- 由于 panic、recover 参数类型为 interface{},因此可抛出任何类型对象。
``
func panic(v interface{})
func recover() interface{}
- 延迟调用中引发的错误,可被后续延迟调用捕获,但仅最后一个错误可被捕获。
```
func test() {
defer func() {
fmt.Println(recover())
}()
defer func() {
panic("defer panic")
}()
panic("test panic")
}
func main() {
test()
}
```
输出:
``
defer panic
- 捕获函数 recover 只有在延迟调用内直接调用才会终止错误,否则总是返回 nil。任何未捕获的错误都会沿调用堆栈向外传递。
```
func test() {
defer recover() // 无效!
defer fmt.Println(recover()) // 无效!
defer func() {
func() {
println("defer inner")
recover() // 无效!
}()
}()
panic("test panic")
}
func main() {
test()
}
```
输出:
``
defer inner
<nil>
panic: test panic
- 使用延迟匿名函数或下面这样都是有效的。
```
func except() {
recover()
}
func test() {
defer except()
panic("test panic")
}
```
- 如果需要保护代码片段,可将代码块重构成匿名函数,如此可确保后续代码被执行。
``
func test(x, y int) {
var z int
func() {
defer func() {
if recover() != nil { z = 0 }
}()
z = x / y
return
}()
println("x / y =", z)
}
- 除用 panic 引发中断性错误外,还可返回 error 类型错误对象来表示函数调用状态。
``
type error interface {
Error() string
}
- 标准库 errors.New 和 fmt.Errorf 函数用于创建实现 error 接口的错误对象。通过判断错误对象实例来确定具体错误类型。
```
var ErrDivByZero = errors.New("division by zero")
func div(x, y int) (int, error) {
if y == 0 { return 0, ErrDivByZero }
return x / y, nil
}
func main() {
switch z, err := div(10, 0); err {
case nil:
println(z)
case ErrDivByZero:
panic(err)
}
}
```
- 如何区别使用 panic 和 error 两种方式?惯例是:导致关键流程出现不可修复性错误的使用 panic,其他使用 error。
4.语言详解--数据
4.0 字符串
- 字符串是不可变字节(byte)序列,其本身是一个复合结构。
``
type stringStruct struct {
str unsafe.pointer
len int
}
- 头部指针指向字节数组,但是没有NULL结尾。默认以utf-8编码存储Unicode字符,字面量里允许使用十六进制、八进制和UTF编码格式。
```
func main() {
s := "路人甲\61\142\u0041"
fmt.Printf("%s\n, s")
fmt.printf("&x, len:%d\n", s, len(s))
}
```
输出:
``
test2.go 试试就知道了。
- 内置函数len返回字节数组长度,cap不接受字符串类型参数。
- 字符串默认值不是nil,而是"".
- 使用""定义不做转义处理的原始字符串(raw string),支持跨行。
- 编译器不会解析原始字符串内的注释语句,且前置缩进空格也属于字符串内容。
- 支持!= == < > + +=操作符
如
``
s := "ab" +
"cd" //跨行时候假发操作符必须在上一行结尾。
- 允许以索引号访问字节数组(非字符),但是不能获取元素地址。
如
```
func main() {
s := "abc"
println(s[1])
println(&s[1]) //error: cannot take the address of s[1]
}
```
- 以切片语法(其实和结束索引号)返回子串时,其内部依旧只想原字节数组。
- 使用for遍历字符串时,分byte和rune两种方法。rune:返回数组索引号以及Unicode字符。
转换
- 要修改字符串,需要将其转换为可变类型 rune byte ,待完成后再转换回来,但是不管如何转换都需要重新分配内存,并复制数据。
4.1 Array
和以往认知的数组有很大不同。
- 数组是值类型,赋值和传参会复制整个数组,而不是指针。
- 数组⻓长度必须是常量,且是类型的组成部分。[2]int 和 [3]int 是不同类型。
- 支持 "=="、"!=" 操作符,因为内存总是被初始化过的。
- 指针数组 [n]T,数组指针 [n]T。
- 可用复合语句初始化。
```
a := [3]int{1, 2} // 未初始化元素值为 0。
b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。
c := [5]int{2: 100, 4:200} // 使用索引号初始化元素。
d := [...]struct {
name string
age uint8
}{
{"user1", 10}, // 可省略元素类型。
{"user2", 20}, // 别忘了最后一行的逗号。
}
```
- 支持多维数组。
``
a := [2][3]int{{1, 2, 3}, {4, 5, 6}}
b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。
- 值拷贝行为会造成性能问题,通常会建议使用 slice,或数组指针。
```
func test(x [2]int) {
fmt.Printf("x: %p\n", &x)
x[1] = 1000
}
func main() {
a := [2]int{}
fmt.Printf("a: %p\n", &a)
test(a)
fmt.Println(a)
}
```
输出:
``
a: 0x2101f9150
x: 0x2101f9170
[0 0]
- 内置函数 len 和 cap 都返回数组长度 (元素数量)。
``
a := [2]int{}
println(len(a), cap(a)) // 2, 2
4.2 Slice
- 需要说明,slice 并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案。
<b>runtime.h
``
struct Slice
{ // must not move anything
byte* array; // actual data
uintgo len; // number of elements
uintgo cap; // allocated number of elements
};
- 引用类型。但自身是结构体,值拷贝传递。
- 属性 len 表⽰示可用元素数量,读写操作不能超过该限制。
- 属性 cap 表⽰示最大扩张容量,不能超出数组限制。
- 如果 slice == nil,那么 len、cap 结果都等于 0。
``
data := [...]int{0, 1, 2, 3, 4, 5, 6}
slice := data[1:4:5] // [low : high : max]
``
+- low high-+ +- max len = high - low
| | | cap = max - low
+----+----+----+----+----+----+----+ +---------+---------+---------+
data | 0 | 1 | 2 | 3 | 4 | 5 | 6 | slice | pointer | len = 3 | cap = 4 |
+----+----+----+----+----+----+----+ +---------+---------+---------+
|<--- len ---->| | |
| | |
|<----- cap ------->| |
| |
+-------<<<-------- slice.array pointer ---<<<-----+
- 创建表达式使用的是元素索引号,而非数量。
``
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
expression slice len cap comment
------------+-------------------------+---------+---------+---------------------
data[:6:8] [0 1 2 3 4 5] 6 8 省略low.
data[5:] [5 6 7 8 9] 5 5 省略high、max。
data[:3] [0 1 2] 3 10 省略low、max。
data[:] [0 1 2 3 4 5 6 7 8 9] 10 10 全部省略。
- 读写操作实际目标是底层数组,只需注意索引号的差别。
```
data := [...]int{0, 1, 2, 3, 4, 5}
s := data[2:4]
s[0] += 100
s[1] += 200
fmt.Println(s)
fmt.Println(data)
```
输出:
``
[102 203]
[0 1 102 203 4 5]
- 可直接创建 slice 对象,自动分配底层数组。
``
s1 := []int{0, 1, 2, 3, 8: 100} // 通过初始化表达式构造,可使用索引号。
fmt.Println(s1, len(s1), cap(s1))
s2 := make([]int, 6, 8) // 使用 make 创建,指定 len 和 cap 值。
fmt.Println(s2, len(s2), cap(s2))
s3 := make([]int, 6) // 省略 cap,相当于 cap = len。
fmt.Println(s3, len(s3), cap(s3))
输出:
``
[0 1 2 3 0 0 0 0 100] 9 9
[0 0 0 0 0 0] 6 8
[0 0 0 0 0 0] 6 6
- 使用 make 动态创建 slice,避免了数组必须用常量做长度的麻烦。还可用指针直接访问底层数组,退化成普通数组操作。
```
s := []int{0, 1, 2, 3}
p := &s[2] // int, 获取底层数组元素指针。
p += 100
fmt.Println(s)
```
输出:
``
[0 1 102 3]
- 至于 \[\]\[\]T,是指元素类型为 \[\]T 。
``
data := [][]int{
[]int{1, 2, 3},
[]int{100, 200},
[]int{11, 22, 33, 44},
}
- 可直接修改 struct array/slice 成员。
```
d := [5]struct {
x int
}{}
s := d[:]
d[1].x = 10
s[2].x = 20
fmt.Println(d)
fmt.Printf("%p, %p\n", &d, &d[0])
```
输出:
``
[{0} {10} {20} {0} {0}]
0x20819c180, 0x20819c180
4.2.1 reslice
- 所谓 reslice,是基于已有 slice 创建新 slice 对象,以便在 cap 允许范围内调整属性。
``
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := s[2:5] // [2 3 4]
s2 := s1[2:6:7] // [4 5 6 7]
s3 := s2[3:6] // Error
``
+---+---+---+---+---+---+---+---+---+---+
data | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
+---+---+---+---+---+---+---+---+---+---+
0 2 5
+---+---+---+---+---+---+---+---+
s1 | 2 | 3 | 4 | | | | | | len = 3, cap = 8
+---+---+---+---+---+---+---+---+
0 2 6 7
+---+---+---+---+---+
s2 | 4 | 5 | 6 | 7 | | len = 4, cap = 5
+---+---+---+---+---+
0 3 4 5
+---+---+---+
s3 | 7 | 8 | X | error: slice bounds out of range
+---+---+---+
- 新对象依旧指向原底层数组。
```
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := s[2:5] // [2 3 4]
s1[2] = 100
s2 := s1[2:6] // [100 5 6 7]
s2[3] = 200
fmt.Println(s)
```
输出:
``
[0 1 2 3 100 5 6 200 8 9]
4.2.2 append
- 向 slice 尾部添加数据,返回新的 slice 对象。
```
s := make([]int, 0, 5)
fmt.Printf("%p\n", &s)
s2 := append(s, 1)
fmt.Printf("%p\n", &s2)
fmt.Println(s, s2)
```
输出:
``
0x210230000
0x210230040
[] [1]
- 简单点说,就是在 array\[slice.high\] 写数据。
```
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s := data[:3]
s2 := append(s, 100, 200) // 添加多个值。
fmt.Println(data)
fmt.Println(s)
fmt.Println(s2)
```
输出:
``
[0 1 2 100 200 5 6 7 8 9]
[0 1 2]
[0 1 2 100 200]
- 一旦超出原 slice.cap 限制,就会重新分配底层数组,即便原数组并未填满。
```
data := [...]int{0, 1, 2, 3, 4, 10: 0}
s := data[:2:3]
s = append(s, 100, 200) // 一次 append 两个值,超出 s.cap 限制。
fmt.Println(s, data) // 重新分配底层数组,与原数组无关。
fmt.Println(&s[0], &data[0]) // 比对底层数组起始指针。
```
输出:
``
[0 1 100 200] [0 1 2 3 4 0 0 0 0 0 0]
0x20819c180 0x20817c0c0
- 从输出结果可以看出,append 后的 s 重新分配了底层数组,并复制数据。如果只追加一个值,则不会超过 s.cap 限制,也就不会重新分配。
- 通常以 2 倍容量重新分配底层数组。在大批量添加数据时,建议一次性分配足够大的空间,以减少内存分配和数据复制开销。或初始化足够长的 len 属性,改用索引号进行操作。及时释放不再使用的 slice 对象,避免持有过期数组,造成 GC 无法回收。
```
s := make([]int, 0, 1)
c := cap(s)
for i := 0; i < 50; i++ {
s = append(s, i)
if n := cap(s); n > c {
fmt.Printf("cap: %d -> %d\n", c, n)
c = n
}
}
```
输出:
``
cap: 1 -> 2
cap: 2 -> 4
cap: 4 -> 8
cap: 8 -> 16
cap: 16 -> 32
cap: 32 -> 64
4.2.3 copy
- 函数 copy 在两个 slice 间复制数据,复制长度以 len 小的为准。两个 slice 可指向同一底层数组,允许元素区间重叠。
```
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s := data[8:]
s2 := data[:5]
copy(s2, s) // dst:s2, src:s
fmt.Println(s2)
fmt.Println(data)
```
输出:
``
[8 9 2 3 4]
[8 9 2 3 4 5 6 7 8 9]
- 应及时将所需数据 copy 到较小的 slice,以便释放超大号底层数组内存。
4.3 Map
- 引用类型,哈希表。键必须是⽀支持相等运算符 (==、!=) 类型,比如 number、string、pointer、array、struct,以及对应的 interface。值可以是任意类型,没有限制。
```
m := map[int]struct {
name string
age int
}{
1: {"user1", 10}, // 可省略元素类型。
2: {"user2", 20},
}
println(m[1].name)
```
- 预先给 make 函数一个合理元素数量参数,有助于提升性能。因为事先申请一大块内存,可避免后续操作时频繁扩张。
``
m := make(map[string]int, 1000)
常见操作:
```
m := map[string]int{
"a": 1,
}
if v, ok := m["a"]; ok { // 判断 key 是否存在。
println(v)
}
println(m["c"]) // 对于不存在的 key,直接返回 \0,不会出错。
m["b"] = 2 // 新增或修改。
delete(m, "c") // 删除。如果 key 不存在,不会出错。
println(len(m)) // 获取键值对数量。cap 无效。
for k, v := range m { // 迭代,可仅返回 key。随机顺序返回,每次都不相同。
println(k, v)
}
```
- 不能保证迭代返回次序,通常是随机结果,具体和版本实现有关。从 map 中取回的是一个 value 临时复制品,对其成员的修改是没有任何意义的。
```
type user struct{ name string }
m := map[int]user{ // 当 map 因扩张而重新哈希时,各键值项存储位置都会发生改变。 因此,map
1: {"user1"}, // 被设计成 not addressable。 类似 m[1].name 这种期望透过原 value
} // 指针修改成员的行为自然会被禁止。
m[1].name = "Tom" // Error: cannot assign to m[1].name
```
正确做法是完整替换 value 或使用指针。
```
u := m[1]
u.name = "Tom"
m[1] = u // 替换 value。
m2 := map[int]*user{
1: &user{"user1"},
}
m2[1].name = "Jack" // 返回的是指针复制品。透过指针修改原对象是允许的。可以在迭代时安全删除键值。但如果期间有新增操作,那么就不知道会有什么意外了。
for i := 0; i < 5; i++ {
m := map[int]string{
0: "a", 1: "a", 2: "a", 3: "a", 4: "a",
5: "a", 6: "a", 7: "a", 8: "a", 9: "a",
}
for k := range m {
m[k+k] = "x"
delete(m, k)
}
fmt.Println(m)
}
```
输出:
``
map[12:x 16:x 2:x 6:x 10:x 14:x 18:x]
map[12:x 16:x 20:x 28:x 36:x]
map[12:x 16:x 2:x 6:x 10:x 14:x 18:x]
map[12:x 16:x 2:x 6:x 10:x 14:x 18:x]
map[12:x 16:x 20:x 28:x 36:x]
4.4 Struct
- 值类型,赋值和传参会复制全部内容。可用 _ 定义补位字段,支持指向自身类型的指针成员。
```
type Node struct {
_ int
id int
data byte
next Node
}
func main() {
n1 := Node{
id: 1,
data: nil,
}
n2 := Node{
id: 2,
data: nil,
next: &n1,
}
}
```
- 顺序初始化必须包含全部字段,否则会出错。
```
type User struct {
name string
age int
}
u1 := User{"Tom", 20}
u2 := User{"Tom"} // Error: too few values in struct initializer
```
- 支持匿名结构,可用作结构成员或定义变量。
```
type File struct {
name string
size int
attr struct {
perm int
owner int
}
}
f := File{
name: "test.txt",
size: 1025,
// attr: {0755, 1}, // Error: missing type in composite literal
}
f.attr.owner = 1
f.attr.perm = 0755
var attr = struct {
perm int
owner int
}{2, 0755}
f.attr = attr
```
- 支持 "=="、"!=" 相等操作符,可用作 map 键类型。
```
type User struct {
id int
name string
}
m := map[User]int{
User{1, "Tom"}: 100,
}
```
- 可定义字段标签,用反射读取。标签是类型的组成部分。
``
var u1 struct { name string "username" }
var u2 struct { name string }
u2 = u1 // Error: cannot use u1 (type struct { name string "username" }) as
// type struct { name string } in assignment
- 空结构 "节省" 内存,比如用来实现 set 数据结构,或者实现没有 "状态" 只有方法的 "静态类"。
``
var null struct{}
set := make(map[string]struct{})
set["a"] = null
4.4.1 匿名字段
- 匿名字段不过是一种语法糖,从根本上说,就是一个与成员类型同名 (不含包名) 的字段。被匿名嵌入的可以是任何类型,当然也包括指针。
```
type User struct {
name string
}
type Manager struct {
User
title string
}
m := Manager{
User: User{"Tom"}, // 匿名字段的显式字段名,和类型名相同。
title: "Administrator",
}
```
- 可以像普通字段那样访问匿名字段成员,编译器从外向内逐级查找所有层次的匿名字段,直到发现目标或出错。
```
type Resource struct {
id int
}
type User struct {
Resource
name string
}
type Manager struct {
User
title string
}
var m Manager
m.id = 1
m.name = "Jack"
m.title = "Administrator"
```
- 外层同名字段会遮蔽嵌入字段成员,相同层次的同名字段也会让编译器无所适从。解决方法是使用显式字段名。
```
type Resource struct {
id int
name string
}
type Classify struct {
id int
}
type User struct {
Resource // Resource.id 与 Classify.id 处于同一层次。
Classify
name string // 遮蔽 Resource.name。
}
u := User{
Resource{1, "people"},
Classify{100},
"Jack",
}
println(u.name) // User.name: Jack
println(u.Resource.name) // people
// println(u.id) // Error: ambiguous selector u.id
println(u.Classify.id) // 100
```
- 不能同时嵌入某一类型和其指针类型,因为它们名字相同。
```
type Resource struct {
id int
}
type User struct {
*Resource
// Resource // Error: duplicate field Resource
name string
}
u := User{
&Resource{1},
"Administrator",
}
println(u.id)
println(u.Resource.id)
```
4.4.2 面向对象
- 面向对象三大特征里,Go 仅支持封装,尽管匿名字段的内存布局和行为类似继承。没有class 关键字,没有继承、多态等等。
```
type User struct {
id int
name string
}
type Manager struct {
User
title string
}
m := Manager{User{1, "Tom"}, "Administrator"}
// var u User = m // Error: cannot use m (type Manager) as type User in assignment
// 没有继承,自然也不会有多态。
var u User = m.User // 同类型拷贝。
```
- 内存布局和 C struct 相同,没有任何附加的 object 信息。
``
|<-------- User:24 ------->|<-- title:16 -->|
+--------------+-----------+----------------+ +---------------+
m | 1 | string | string | | Administrator | [n]byte
+--------------+-----------+----------------+ +---------------+
| | |
| | +--->>>------------------->>>------+
|
+--->>>-------------------------------->>>----+
| |
+--------->>>------------------------------>>>-+ | |
| | |
+-----------+-------------+ +---------+
u | 1 | string | | Tom | [n]byte
+-----------+-------------+ +---------+
|<- id:8 -->|<- name:16 ->|
- 可用 unsafe 包相关函数输出内存地址信息。
``
m : 0x2102271b0, size: 40, align: 8
m.id : 0x2102271b0, offset: 0
m.name : 0x2102271b8, offset: 8
m.title: 0x2102271c8, offset: 24
5.语言详解--方法
5.1 方法定义
方法总是绑定对象实例,并隐式将实例作为第一实参 (receiver)。
- 只能为当前包内命名类型定义方法。
- 参数 receiver 可任意命名。如方法中未曾使⽤用,可省略参数名。
- 参数 receiver 类型可以是 T 或 *T。基类型 T 不能是接口或指针。
- 不支持方法重载,receiver 只是参数签名的组成部分。
- 可用实例 value 或 pointer 调用全部方法,编译器自动转换。
- 没有构造和析构方法,通常用简单工厂模式返回对象实例。
```
type Queue struct {
elements []interface{}
}
func NewQueue() *Queue { // 创建对象实例。
return &Queue{make([]interface{}, 10)}
}
func (*Queue) Push(e interface{}) error { // 省略 receiver 参数名。
panic("not implemented")
}
// func (Queue) Push(e int) error { // Error: method redeclared: Queue.Push
// panic("not implemented")
// }
func (self *Queue) length() int { // receiver 参数名可以是 self、this 或其他。
return len(self.elements)
}
```
- 方法不过是一种特殊的函数,只需将其还原,就知道 receiver T 和 *T 的差别。
```
type Data struct{
x int
}
func (self Data) ValueTest() { // func ValueTest(self Data);
fmt.Printf("Value: %p\n", &self)
}
func (self Data) PointerTest() { // func PointerTest(self Data);
fmt.Printf("Pointer: %p\n", self)
}
func main() {
d := Data{}
p := &d
fmt.Printf("Data: %p\n", p)
d.ValueTest() // ValueTest(d)
d.PointerTest() // PointerTest(&d)
p.ValueTest() // ValueTest(*p)
p.PointerTest() // PointerTest(p)
}
```
输出:
``
Data : 0x2101ef018
Value : 0x2101ef028
Pointer: 0x2101ef018
Value : 0x2101ef030
Pointer: 0x2101ef018
- 从 1.4 开始,不再支持多级指针查找方法成员。
```
type X struct{}
func (X) test() {
println("X.test")
}
func main() {
p := &X{}
p.test()
// Error: calling method with receiver &p (type *X) requires explicit dereference
// (&p).test()
}
```
5.2 匿名字段
- 可以像字段成员那样访问匿名字段方法,编译器负责查找。
```
type User struct {
id int
name string
}
type Manager struct {
User
}
func (self *User) ToString() string { // receiver = &(Manager.User)
return fmt.Sprintf("User: %p, %v", self, self)
}
func main() {
m := Manager{User{1, "Tom"}}
fmt.Printf("Manager: %p\n", &m)
fmt.Println(m.ToString())
}
```
输出:
``
Manager: 0x2102281b0
User : 0x2102281b0, &{1 Tom}
- 通过匿名字段,可获得和继承类似的复用能⼒力。依据编译器查找次序,只需在外层定义同名方法,就可以实现 "override"。
```
type User struct {
id int
name string
}
type Manager struct {
User
title string
}
func (self *User) ToString() string {
return fmt.Sprintf("User: %p, %v", self, self)
}
func (self *Manager) ToString() string {
return fmt.Sprintf("Manager: %p, %v", self, self)
}
func main() {
m := Manager{User{1, "Tom"}, "Administrator"}
fmt.Println(m.ToString())
fmt.Println(m.User.ToString())
}
```
输出:
``
Manager: 0x2102271b0, &{{1 Tom} Administrator}
User : 0x2102271b0, &{1 Tom}
5.3 方法集
每个类型都有与之关联的方法集,这会影响到接口实现规则。
- 类型 T 方法集包含全部 receiver T 方法。
- 类型 T 方法集包含全部 receiver T + T 方法。
- 如类型 S 包含匿名字段 T,则 S 方法集包含 T 方法。
- 如类型 S 包含匿名字段 T,则 S 方法集包含 T + T 方法。
- 不管嵌入 T 或 T,S 方法集总是包含 T + *T 方法。
- 用实例 value 和 pointer 调用方法 (含匿名字段) 不受方法集约束,编译器总是查找全部方法,并自动转换 receiver 实参。
5.4 表达式
- 根据调用者不同,方法分为两种表现形式:
``
instance.method(args...) ---> <type>.func(instance, args...)
- 前者称为 method value,后者 method expression。
- 两者都可像普通函数那样赋值和传参,区别在于 method value 绑定实例,而 method expression 则须显式传参。
```
type User struct {
id int
name string
}
func (self *User) Test() {
fmt.Printf("%p, %v\n", self, self)
}
func main() {
u := User{1, "Tom"}
u.Test()
mValue := u.Test
mValue() // 隐式传递 receiver
mExpression := (*User).Test
mExpression(&u) // 显式传递 receiver
}
```
输出:
``
0x210230000, &{1 Tom}
0x210230000, &{1 Tom}
0x210230000, &{1 Tom}
- 需要注意,method value 会复制 receiver。
```
type User struct {
id int
name string
}
func (self User) Test() {
fmt.Println(self)
}
func main() {
u := User{1, "Tom"}
mValue := u.Test // 立即复制 receiver,因为不是指针类型,不受后续修改影响。
u.id, u.name = 2, "Jack"
u.Test()
mValue()
}
```
输出:
``
{2 Jack}
{1 Tom}
- 在汇编层面,method value 和闭包的实现方式相同,实际返回 FuncVal 类型对象。
``
FuncVal { method_address, receiver_copy }
- 可依据方法集转换 method expression,注意 receiver 类型的差异。
```
type User struct {
id int
name string
}
func (self *User) TestPointer() {
fmt.Printf("TestPointer: %p, %v\n", self, self)
}
func (self User) TestValue() {
fmt.Printf("TestValue: %p, %v\n", &self, self)
}
func main() {
u := User{1, "Tom"}
fmt.Printf("User: %p, %v\n", &u, u)
mv := User.TestValue
mv(u)
mp := (User).TestPointer
mp(&u)
mp2 := (User).TestValue // User 方法集包含 TestValue。
mp2(&u) // 签名变为 func TestValue(self User)。
} // 实际依然是 receiver value copy。
```
输出:
``
User : 0x210231000, {1 Tom}
TestValue : 0x210231060, {1 Tom}
TestPointer: 0x210231000, &{1 Tom}
TestValue : 0x2102310c0, {1 Tom}
- 将方法 "还原" 成函数,就容易理解下面的代码了。
```
type Data struct{}
func (Data) TestValue() {}
func (*Data) TestPointer() {}
func main() {
var p Data = nil
p.TestPointer()
(Data)(nil).TestPointer() // method value
(*Data).TestPointer(nil) // method expression
// p.TestValue() // invalid memory address or nil pointer dereference
// (Data)(nil).TestValue() // cannot convert nil to type Data
// Data.TestValue(nil) // cannot use nil as type Data in function argument
}
```
6.语言详解--接口
6.1 接口定义
- 接口是一个或多个方法签名的集合,任何类型的方法集中只要拥有与之对应的全部方法,就表示它 "实现" 了该接口,无须在该类型上显式添加接口声明。
- 所谓对应方法,是指有相同名称、参数列表 (不包括参数名) 以及返回值。当然,该类型还可以有其他方法。
- 接口命名习惯以 er 结尾,结构体。
- 接口只有方法签名,没有实现。
- 接口没有数据字段。
- 可在接口中嵌⼊入其他接口。
- 类型可实现多个接口。
```
type Stringer interface {
String() string
}
type Printer interface {
Stringer // 接口嵌入。
Print()
}
type User struct {
id int
name string
}
func (self *User) String() string {
return fmt.Sprintf("user %d, %s", self.id, self.name)
}
func (self *User) Print() {
fmt.Println(self.String())
}
func main() {
var t Printer = &User{1, "Tom"} // *User 方法集包含 String、Print。
t.Print()
}
```
输出:
``
user 1, Tom
- 空接口 interface{} 没有任何方法签名,也就意味着任何类型都实现了空接口。其作用类似面向对象语言中的根对象object。
```
func Print(v interface{}) {
fmt.Printf("%T: %v\n", v, v)
}
func main() {
Print(1)
Print("Hello, World!")
}
```
输出:
``
int: 1
string: Hello, World!
- 匿名接口可用作变量类型,或结构成员。
```
type Tester struct {
s interface {
String() string
}
}
type User struct {
id int
name string
}
func (self *User) String() string {
return fmt.Sprintf("user %d, %s", self.id, self.name)
}
func main() {
t := Tester{&User{1, "Tom"}}
fmt.Println(t.s.String())
}
```
输出:
``
user 1, Tom
6.2 执行机制
- 接口对象由接口表 (interface table) 指针和数据指针组成。
> runtime.h
``
struct Iface
{
Itab tab;
void data;
};
struct Itab
{
InterfaceType inter;
Type type;
void (*fun[])(void);
};
- 接口表存储元数据信息,包括接口类型、动态类型,以及实现接口的方法指针。无论是反射还是通过接口调用方法,都会用到这些信息。
- 数据指针持有的是目标对象的只读复制品,复制完整对象或指针。
```
type User struct {
id int
name string
}
func main() {
u := User{1, "Tom"}
var i interface{} = u
u.id = 2
u.name = "Jack"
fmt.Printf("%v\n", u)
fmt.Printf("%v\n", i.(User))
}
```
输出:
``
{2 Jack}
{1 Tom}
- 接口转型返回临时对象,只有使⽤用指针才能修改其状态。
```
type User struct {
id int
name string
}
func main() {
u := User{1, "Tom"}
var vi, pi interface{} = u, &u
// vi.(User).name = "Jack" // Error: cannot assign to vi.(User).name
pi.(*User).name = "Jack"
fmt.Printf("%v\n", vi.(User))
fmt.Printf("%v\n", pi.(*User))
}
```
输出:
``
{1 Tom}
&{1 Jack}
- 只有 tab 和 data 都为 nil 时,接口才等于 nil。
```
var a interface{} = nil // tab = nil, data = nil
var b interface{} = (int)(nil) // tab 包含 int 类型信息, data = nil
type iface struct {
itab, data uintptr
}
ia := (iface)(unsafe.Pointer(&a))
ib := (iface)(unsafe.Pointer(&b))
fmt.Println(a == nil, ia)
fmt.Println(b == nil, ib, reflect.ValueOf(b).IsNil())
```
输出:
``
true {0 0}
false {505728 0} true
6.3 接口转换
- 利用类型推断,可判断接口对象是否某个具体的接口或类型。
```
type User struct {
id int
name string
}
func (self *User) String() string {
return fmt.Sprintf("%d, %s", self.id, self.name)
}
func main() {
var o interface{} = &User{1, "Tom"}
if i, ok := o.(fmt.Stringer); ok { // ok-idiom
fmt.Println(i)
}
u := o.(User)
// u := o.(User) // panic: interface is main.User, not main.User
fmt.Println(u)
}
```
- 还可用 switch 做批量类型判断,不支持 fallthrough。
```
func main() {
var o interface{} = &User{1, "Tom"}
switch v := o.(type) {
case nil: // o == nil
fmt.Println("nil")
case fmt.Stringer: // interface
fmt.Println(v)
case func() string: // func
fmt.Println(v())
case User: // struct
fmt.Printf("%d, %s\n", v.id, v.name)
default:
fmt.Println("unknown")
}
}
```
- 超集接口对象可转换为子集接口,反之出错。
```
type Stringer interface {
String() string
}
type Printer interface {
String() string
Print()
}
type User struct {
id int
name string
}
func (self *User) String() string {
return fmt.Sprintf("%d, %v", self.id, self.name)
}
func (self *User) Print() {
fmt.Println(self.String())
}
func main() {
var o Printer = &User{1, "Tom"}
var s Stringer = o
fmt.Println(s.String())
}
```
6.4 接口技巧
让编译器检查,以确保某个类型实现接口。
``
var _ fmt.Stringer = (*Data)(nil)
- 某些时候,让函数直接 "实现" 接口能省不少事。
``
type Tester interface {
Do()
}
type FuncDo func()
func (self FuncDo) Do() { self() }
func main() {
var t Tester = FuncDo(func() { println("Hello, World!") })
t.Do()
}
7.语言详解--并发
7.1 Goroutine
- Go 在语言层面对并发编程提供支持,一种类似协程,称作 goroutine 的机制。
- 只需在函数调用语句前添加 go 关键字,就可创建并发执行单元。
- 开发人员无需了解任何执行细节,调度器会自动将其安排到合适的系统线程上执行。
- goroutine 是一种非常轻量级的实现,可在单个进程里执行成千上万的并发任务。
- 入口函数 main 就以 goroutine 运行。另有与之配套的 channel 类型,用以实现 "以通讯来共享内存" 的 CSP 模式。
``
go func() {
println("Hello, World!")
}()
- 调度器不能保证多个 goroutine 执行次序,且进程退出时不会等待它们结束。
- 默认情况下,进程启动后仅允许一个系统线程服务于 goroutine。可使用环境变量或标准库函数 runtime.GOMAXPROCS 修改,让调度器用多个线程实现多核并行,而不仅仅是并发。
```
func sum(id int) {
var x int64
for i := 0; i < math.MaxUint32; i++ {
x += int64(i)
}
println(id, x)
}
func main() {
wg := new(sync.WaitGroup)
wg.Add(2)
for i := 0; i < 2; i++ {
go func(id int) {
defer wg.Done()
sum(id)
}(i)
}
wg.Wait()
}
```
输出:
``
$ go build -o test
$ time -p ./test
0 9223372030412324865
1 9223372030412324865
real 7.70 // 程序开始到结束时间差 (非 CPU 时间)
user 7.66 // 用户态所使用 CPU 时间片 (多核累加)
sys 0.01 // 内核态所使用 CPU 时间片
$ GOMAXPROCS=2 time -p ./test
0 9223372030412324865
1 9223372030412324865
real 4.18
user 7.61 // 虽然总时间差不多,但由 2 个核并行,real 时间自然少了许多。
sys 0.02
- 调用 runtime.Goexit 将立即终止当前 goroutine 执行,调度器确保所有已注册 defer延迟调用被执行。
```
func main() {
wg := new(sync.WaitGroup)
wg.Add(1)
go func() {
defer wg.Done()
defer println("A.defer")
func() {
defer println("B.defer")
runtime.Goexit() // 终止当前 goroutine
println("B") // 不会执行
}()
println("A") // 不会执行
}()
wg.Wait()
}
```
输出:
``
B.defer
A.defer
- 和协程 yield 作用类似,Gosched 让出底层线程,将当前 goroutine 暂停,放回队列等待下次被调度执行。
```
func main() {
wg := new(sync.WaitGroup)
wg.Add(2)
go func() {
defer wg.Done()
for i := 0; i < 6; i++ {
println(i)
if i == 3 { runtime.Gosched() }
}
}()
go func() {
defer wg.Done()
println("Hello, World!")
}()
wg.Wait()
}
```
输出:
``
$ go run main.go
0
1
2
3
Hello, World!
4
5
7.2 Channel
- 引用类型 channel 是 CSP 模式的具体实现,用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。
- 默认为同步模式,需要发送和接收配对。否则会被阻塞,直到另一方准备好后被唤醒。
```
func main() {
data := make(chan int) // 数据交换队列
exit := make(chan bool) // 退出通知
go func() {
for d := range data { // 从队列迭代接收数据,直到 close 。
fmt.Println(d)
}
fmt.Println("recv over.")
exit <- true // 发出退出通知。
}()
data <- 1 // 发送数据。
data <- 2
data <- 3
close(data) // 关闭队列。
fmt.Println("send over.")
<-exit // 等待退出通知。
}
```
输出:
``
1
2
3
send over.
recv over.
- 异步方式通过判断缓冲区来决定是否阻塞。如果缓冲区已满,发送被阻塞;缓冲区为空,接收被阻塞。
- 通常情况下,异步 channel 可减少排队阻塞,具备更高的效率。但应该考虑使用指针规避大对象拷贝,将多个元素打包,减小缓冲区大小等。
```
func main() {
data := make(chan int, 3) // 缓冲区可以存储 3 个元素
exit := make(chan bool)
data <- 1 // 在缓冲区未满前,不会阻塞。
data <- 2
data <- 3
go func() {
for d := range data { // 在缓冲区未空前,不会阻塞。
fmt.Println(d)
}
exit <- true
}()
data <- 4 // 如果缓冲区已满,阻塞。
data <- 5
close(data)
<-exit
}
```
- 缓冲区是内部属性,并非类型构成要素。
``
var a, b chan int = make(chan int), make(chan int, 3)
- 除用 range 外,还可用 ok-idiom 模式判断 channel 是否关闭。
``
for {
if d, ok := <-data; ok {
fmt.Println(d)
} else {
break
}
}
- 向 closed channel 发送数据引发 panic 错误,接收立即返回零值。而 nil channel无论收发都会被阻塞。
- 内置函数 len 返回未被读取的缓冲元素数量,cap 返回缓冲区大小。
``
d1 := make(chan int)
d2 := make(chan int, 3)
d2 <- 1
fmt.Println(len(d1), cap(d1)) // 0 0
fmt.Println(len(d2), cap(d2)) // 1 3
7.2.1 单向
- 可以将 channel 隐式转换为单向队列,只收或只发。
``
c := make(chan int, 3)
var send chan<- int = c // send-only
var recv <-chan int = c // receive-only
send <- 1
// <-send // Error: receive from send-only type chan<- int
<-recv
// recv <- 2 // Error: send to receive-only type <-chan int
- 不能将单向 channel 转换为普通 channel。
``
d := (chan int)(send) // Error: cannot convert type chan<- int to type chan int
d := (chan int)(recv) // Error: cannot convert type <-chan int to type chan int
7.2.2 选择
- 如果需要同时处理多个 channel,可使用 select 语句。它随机选择一个可用 channel 做收发操作,或执行 default case。
```
func main() {
a, b := make(chan int, 3), make(chan int)
go func() {
v, ok, s := 0, false, ""
for {
select { // 随机选择可用 channel,接收数据。
case v, ok = <-a: s = "a"
case v, ok = <-b: s = "b"
}
if ok {
fmt.Println(s, v)
} else {
os.Exit(0)
}
}
}()
for i := 0; i < 5; i++ {
select { // 随机选择可用 channel,发送数据。
case a <- i:
case b <- i:
}
}
close(a)
select {} // 没有可用 channel,阻塞 main goroutine。
}
```
输出:
``
b 3
a 0
a 1
a 2
b 4
- 在循环中使用 select default case 需要小心,避免形成洪水。
7.2.3 模式
- 用简单工厂模式打包并发任务和 channel。
```
func NewTest() chan int {
c := make(chan int)
rand.Seed(time.Now().UnixNano())
go func() {
time.Sleep(time.Second)
c <- rand.Int()
}()
return c
}
func main() {
t := NewTest()
println(<-t) // 等待 goroutine 结束返回。
}
```
- 用 channel 实现信号量 (semaphore)。
```
func main() {
wg := sync.WaitGroup{}
wg.Add(3)
sem := make(chan int, 1)
for i := 0; i < 3; i++ {
go func(id int) {
defer wg.Done()
sem <- 1 // 向 sem 发送数据,阻塞或者成功。
for x := 0; x < 3; x++ {
fmt.Println(id, x)
}
<-sem // 接收数据,使得其他阻塞 goroutine 可以发送数据。
}(i)
}
wg.Wait()
}
```
输出:
``
$ GOMAXPROCS=2 go run main.go
0 0
0 1
0 2
1 0
1 1
1 2
2 0
2 1
2 2
- 用 closed channel 发出退出通知。
``
func main() {
var wg sync.WaitGroup
quit := make(chan bool)
for i := 0; i < 2; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
task := func() {
println(id, time.Now().Nanosecond())
time.Sleep(time.Second)
}
for {
select {
case <-quit: // closed channel 不会阻塞,因此可用作退出通知。
return
default: // 执行正常任务。
task()
}
}
}(i)
}
time.Sleep(time.Second * 5) // 让测试 goroutine 运行一会。
close(quit) // 发出退出通知。
wg.Wait()
}
- 用 select 实现超时 (timeout)。
```
func main() {
w := make(chan bool)
c := make(chan int, 2)
go func() {
select {
case v := <-c: fmt.Println(v)
case <-time.After(time.Second * 3): fmt.Println("timeout.")
}
w <- true
}()
// c <- 1 // 注释掉,引发 timeout。
<-w
}
```
- channel 是第一类对象,可传参 (内部实现为指针) 或者作为结构成员。
```
type Request struct {
data []int
ret chan int
}
func NewRequest(data ...int) *Request {
return &Request{ data, make(chan int, 1) }
}
func Process(req *Request) {
x := 0
for _, i := range req.data {
x += i
}
req.ret <- x
}
func main() {
req := NewRequest(10, 20, 30)
Process(req)
fmt.Println(<-req.ret)
}
```
其实学完并发,就可以开始写项目了,算是完成go比较关键的部分了。
8.语言详解--包结构
8.1 工作空间
- 编译工具对源码目录有严格要求,每个工作空间 (workspace) 必须由 bin、pkg、src 三个目录组成。(参见test目录)
``
workspace
|
+--- bin // go install 安装目录。
| |
| +--- learn
|
|
+--- pkg // go build 生成静态库 (.a) 存放目录。
| |
| +--- darwin_amd64
| |
| +--- mylib.a
| |
| +--- mylib
| |
| +--- sublib.a
|
+--- src // 项目源码目录。
|
+--- learn
| |
| +--- main.go
|
|
+--- mylib
|
+--- mylib.go
|
+--- sublib
|
+--- sublib.go
- 可在 GOPATH 环境变量列表中添加多个工作空间,但不能和 GOROOT 相同。
export GOPATH=$HOME/projects/golib:$HOME/projects/go
- 通常 go get 使用第一个工作空间保存下载的第三方库。
8.2 源文件
``
编码:源码文件必须是 UTF-8 格式,否则会导致编译器出错。
结束:语句以 ";" 结束,多数时候可以省略。
注释:⽀支持 "//"、"/**/" 两种注释方式,不能嵌套。
命名:采用 camelCasing 风格,不建议使用下划线。
8.3 包结构
- 所有代码都必须组织在 package 中。
- 源文件头部以 "package <name>" 声明包名称。
- 包由同一目录下的多个源码文件组成。
- 包名类似 namespace,与包所在目录名、编译文件名无关。
- 目录名最好不用 main、all、std 这三个保留名称。
- 可执行文件必须包含 package main,入口函数 main。
<b>说明:os.Args 返回命令行参数,os.Exit 终止进程。 <b>要获取正确的可执行文件路径,可用 filepath.Abs(exec.LookPath(os.Args\[0\]))。
<b>包中成员以名称首字母大小写决定访问权限。
- public: 首字母大写,可被包外访问。
- internal: 首字母小写,仅包内成员可以访问。
<b>该规则适用于全局变量、全局常量、类型、结构字段、函数、方法等。
8.3.1 导入包
- 使用包成员前,必须先用 import 关键字导入,但不能形成导入循环。
- import "相对目录/包主文件名"
- 相对目录是指从 <workspace>/pkg/<os\_arch> 开始的子目录,以标准库为例:
``
import "fmt" -> /usr/local/go/pkg/darwin_amd64/fmt.a
import "os/exec" -> /usr/local/go/pkg/darwin_amd64/os/exec.a
- 在导入时,可指定包成员访问方式。比如对包重命名,以避免同名冲突。
``
import "yuhen/test" // 默认模式: test.A
import M "yuhen/test" // 包重命名: M.A
import . "yuhen/test" // 简便模式: A
import _ "yuhen/test" // 非导入模式: 仅让该包执行初始化函数。
- 未使用的导入包,会被编译器视为错误 (不包括 "import _")。
``
./main.go:4: imported and not used: "fmt"
- 对于当前目录下的子包,除使用默认完整导入路径外,还可使用 local 方式。
``
workspace
|
+--- src
|
+--- learn
|
+--- main.go
|
+--- test
|
+--- test.go
> <b>main.go
``
import "learn/test" // 正常模式
import "./test" // 本地模式,仅对 go run main.go 有效。
8.3.2 自定义路径
- 可通过 meta 设置为代码库设置自定义路径。
> <b>server.go
```
package main
import (
"fmt"
"net/http"
)
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprint(w, <meta name="go-import")
content="test.com/finger/test git https://github.com/finger/test">
}
func main() {
http.HandleFunc("/finger/test", handler)
http.ListenAndServe(":80", nil)
}
```
- <b>该示例使用自定义域名 test.com 重定向到 github。
``
$ go get -v test.com/finger/test
Fetching https://test.com/finger/test?go-get=1
https fetch failed.
Fetching http://test.com/finger/test?go-get=1
Parsing meta tags from http://test.com/finger/test?go-get=1 (status code 200)
get "test.com/finger/test": found meta tag http://test.com/finger/test?go-get=1
test.com/finger/test (download)
test.com/finger/test
- 如此,该库就有两个有效导入路径,可能会导致存储两个本地副本。为此,可以给库添加专门的 "import comment"。
- 当 go get 下载完成后,会检查本地存储路径和该注释是否一致。
``
github.com/finger/test/abc.go
package test
// import "test.com/finger/test"
func Hello() {
println("Hello, Custom import path!")
}
- 如继续用 github 路径,会导致 go build 失败。
``
$ go get -v github.com/finger/test
github.com/finger/test (download)
package github.com/finger/test
? imports github.com/finger/test
? imports github.com/finger/test: expects import "test.com/finger/test"
- 这就强制包用户使用唯一路径,也便于日后将包迁移到其他位置。
8.3.3 初始化
- <b>初始化函数:
- 每个源文件都可以定义一个或多个初始化函数
- 编译器不保证多个初始化函数执行次序
- 初始化函数在单一线程被调用,仅执行一次
- 初始化函数在包所有全局变量初始化后执行
- 在所有初始化函数结束后才执行 main.main
- 无法调用初始化函数
- 因为无法保证初始化函数执行顺序,因此全局变量应该直接用 var 初始化。
```
var now = time.Now()
func init() {
fmt.Printf("now: %v\n", now)
}
func init() {
fmt.Printf("since: %v\n", time.Now().Sub(now))
}
```
- 可在初始化函数中使用 goroutine,可等待其结束。
```
var now = time.Now()
func main() {
fmt.Println("main:", int(time.Now().Sub(now).Seconds()))
}
func init() {
fmt.Println("init:", int(time.Now().Sub(now).Seconds()))
w := make(chan bool)
go func() {
time.Sleep(time.Second * 3)
w <- true
}()
<-w
}
```
输出:
``
init: 0
main: 3
- 不应该滥用初始化函数,仅适合完成当前文件中的相关环境设置。
8.4 文档
- <b>扩展工具 godoc 能自动提取注释生成帮助文档。
- 仅和成员相邻 (中间没有空行) 的注释被当做帮助信息。
- 相邻行会合并成同一段落,用空行分隔段落。
- 缩进表示格式化文本,比如示例代码。
- 自动转换 URL 为链接。
- 自动合并多个源码文件中的 package 文档。
- 无法显式 package main 中的成员文档。
8.4.1 Package
- 建议用专门的 doc.go 保存 package 帮助信息。
- 包文档第一整句 (中英文句号结束) 被当做 packages 列表说明。
8.4.2 Example
- 只要 Example 测试函数名称符合以下规范即可。
``
格式 示例
-----------+-------------------------------------------+-----------------------------------
package Example, Example_suffix Example_test
func ExampleF, ExampleF_suffix ExampleHello
type ExampleT, ExampleT_suffix ExampleUser, ExampleUser_copy
method ExampleT_M, ExampleT_M_suffix ExampleUser_ToString
- <font color=red><b>说明:使用 suffix 作为示例名称,其首字母必须小写。如果文件中仅有一个 Example 函数,且调用了该文件中的其他成员,那么示例会显示整个文件内容,而不仅仅是测试函数自己。</font>
8.4.3 Bug
- 非测试源码文件中以 BUG(author) 开始的注释,会在帮助文档 Bugs 节点中显示。// BUG(finger): memory leak.
9.语言详解--反射
9.1 类型
- 反射(reflect)让我们能在运行期弹指对象的类型信息和内存结构,弥补了静态语言上的不足。
- 反射还是实现元编程的重要手段。
- 和C数据结构一样的,GO对象头部并没有类型指针,通过其自身是无法在运行期获知任何类型相关的信息的。反射操作所需要的全部信息都源自接口变量。
- 接口变量除存储自身类型外, 还会保存实际对象的类型数据。
``
func TypeOf(i interface{}) Type
func ValueOf(i interface{}) Value
- 这两个反射入口函数,会将任何传入的对象转换为接口类型。
- 在面对类型时,需要区分type和kind。前者辨识真是类型(静态类型),后者表示其基础结构(底层类型)区别。
```
type x int
func main() {
var a X = 100
t := reflect.TypeOf(a)
fmt.Println(t.Name(), t.kind())
}
```
- 输出:
``
x int
- 所以在类型判断上,需选择正确的方式。
```
type X int
type Y int
func main() {
var a, b x = 100, 200
var c y = 300
ta, tb, tc := reflect.TypeOf(a), reflect.TypeOf(b), reflect.TypeOf(c)
fmt.Println(ta == tb, ta == tc)
fmt.Println(ta.kind() == tc.kind())
}
```
- 输出:
``
true false
true
- 除通过实际对象获取类型外,也可直接构造一些基础符合类型。
```
func main() {
a := reflect.ArrayOf(10, reflect.TypeOf(byte(0)))
m := reflect.MapOf(reflect.TypeOf(""), reflect.TypeOf(0))
fmt.Println(a, m)
}
```
输出:
``
[10]uint8 map[string]int
- 传入对象应区分基类型和指针类型,因为他们并不属于同一类型。
```
func main() {
x := 10
tx, tp := reflect.TypeOf(x), reflect.TypeOf(&x)
fmt.println(tx, tp, tx ==tp)
fmt.Println(tx.kind(), tp.kind())
fmt.Println(tx == tp.Elem())
}
```
输出:
```
int *int false
int ptr
true
```
- 方法Elem返回指针,数据,切片,字典或通道的基类型。
``
func main() {
fmt.Println(reflect.TypeOf(map[string]int()).Elem())
fmt.Println(reflect.TypeOf([]int32{}).Elem())
}
输出:
``
int
int32
- 只有在获取结构体指针的基类型后,才能遍历它的字段。
```
type user struct {
name string
age int
}
type manger struct {
user
title string
}
func main() {
var m manager
t := reflect.TypeOf(&m)
if t.kind() ==reflect.Ptr {
t =t.Elem
}
for i := 0; i < t.NumField();i++ {
f := t.Fiedle(i)
fmt.Println(f.Name, f.Type, f.Offset)
if f.Annoymous {
for x := 0;x < f.Type.NumField();x++ {
af := f.Type.Field(x)
fmt.Println(" ", af.Name, af.Type)
}
}
}
}
```
输出:
``
user main.user 0
name string
age int
title string 24
- 对于匿名字段,可用多级索引(按定义顺序)直接访问。
```
type user struct {
name string
age int
}
type manager struct {
user
title string
}
func main() {
var m manager
t := reflect.TypeOf(m)
name, _ :=t.FieldByName("name") //按照名称查找
fmt.Println(name.Name, name.Type)
age := t.FieldByIndex([]int{0, 1}) //按照多级索引查找
fmt.Println(age.Name, age.Type)
}
```
输出:
``
name string
age int
- FieldByName 不支持多级名称,如有同名遮蔽,需通过匿名字段二次获取。
- 同样的,输出方法集时,一样区分基类型和指针类型。
- 有一点和想想的不用,反射能弹指当前包或外包的非导出结构成员。
- 相对reflect来说,当前包和外包都是“外包”。
- 可用反射提取struct tag ,还能自动分解,。常用于ORM映射,或数据格式验证。
- 辅助判断方法 Implements ConvertibleTo AssignableTo,都是运行期进行动态调用和赋值所必须的。
9.2 值
和type获取类型信息不同value专注于对象实例数据读写。
接口变量会复制对象,且是unaddressable的,所以想修改目标对象,就必须使用指针。
```
func main() {
a := 100
va, vp :=reflect.ValueOf(a), reflect.ValueOf(&a).Elem
fmt.Println(va.CanAddr(), va.CanSet())
fmt.Println(vp.CanAddr(), vp.CanSet())
}
```
输出:
``
false false
true true
- 就算传入指针,一样需要通过elem获取目标对象。因为被接口存储的指针本身是不能寻址和进行设置操作的。
- 不能对非导出字段直接进行设置操纵,无论是当前包还是外包。
- 可通过Interface 方法进行类型推断和转换。
- 复合类型对象设置示例;
- 接口有两种nil状态,这一直是个潜在麻烦。解决方法是用IsNil判断值是否为nil
- 也可用unsafe转换后直接判断iface.data是否为零值。
- value里的某些方法并未实现ok-idom或返回error,所以得自行判断返回的是否为Zero Value
9.3 方法
动态调用方法,谈不上有多麻烦。只需按In列表准备好所需参数即可。
```
type X struct {}
func (X) Test(x, y int) (int, error) {
return x + y, fmt.Errorf("err:%d",x+y)
}
func main() {
var a X
v := reflect.ValueOf(&a)
m := v.MethodByName("TEST")
in := []reflect.Value{
reflect.ValueOf(1),
reflect.ValueOf(2),
}
out := m.Call(in)
for_, v := range out {
fmt.Println(v)
}
}
```
输出:
``
3
err: 3
- 对于变参来说,用CallSlice要更方便一些。
9.4 构建
反射库提供了内置函数make和new的对应操作,其中最有意思的就是makefunc。可用它实现通过模板,适应不同数据类型。
```
//通用算法函数
func add(args []reflect.Value) (results []reflect.Value) {
if len(args) == 0 {
return nil
}
var ret reflect.Value
switch args[0].Kind() {
case reflect.Int:
n := 0
for_, a := range args {
n += int(a, Int())
}
ret = reflect.ValueOf(n)
case reflect.String:
ss := make([]string, 0, len(args))
for_, s := range args {
ss = append(ss, s.String())
}
ret = reflect.ValueOf(strings.Join(ss, ""))
}
results = append(results, ret)
return
}
//将函数指针参数指向通用算法函数
func makeAdd(fptr interface()) {
fn := reflect.ValueOf(fptr).Elem()
v := reflect.MakeFunc(fn, Type(), add()) //zheshi guanjian
fn.Set(v) //指向通用算法函数
}
func main() {
var int&Add func (x, y int) int
var strAdd func(a, b string) string
makeAdd(&intAdd)
makeAdd(&strAdd)
println(intAdd(100, 200))
println(strAdd("hello,"," world!"))
}
```
输出:
``
300
hello, world!
10.语言详解--其他
10.1 内存布局
- 了解对象内存布局,有助于理解值传递、引用传递等概念。
``
+--------+
| 1 | int
+--------+
+--------+
| 3.14 | float32
+--------+
+---+---+---+---+
| 1 | 2 | 3 | 4 | [4]int
+---+---+---+---+
string
``
+---------+---------+
| pointer | len = 5 | s = "hello"
+---------+---------+
|
|
+---+---+---+---+---+
| h | e | l | l | o | [5]byte
+---+---+---+---+---+
|
|
+---------+---------+
| pointer | len = 2 | sub = s[1:3]
+---------+---------+
struct
``
+---+---+---+---+---+---+---+---+
| 1 | 2 | 0 | 0 | 3 | 0 | 0 | 0 | struct { a byte; b byte; c int32 } = { 1, 2, 3 }
+---+---+---+---+---+---+---+---+
a b c
+-----------+-----+
| pointer a | b | struct { a *int; b int }
+-----------+-----+
|
|
+-----+
| int |
+-----+
slice
``
+---------+---------+---------+
| pointer | len = 8 | cap = 8 | x = []int{0, 1, 2, 3, 4, 5, 6, 7 }
+---------+---------+---------+
|
|
+---+---+---+---+---+---+---+---+
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | [8]int
+---+---+---+---+---+---+---+---+
|
|
+---------+---------+---------+
| pointer | len = 2 | cap = 5 | y = x[1:3:6]
+---------+---------+---------+
interface
``
+---------+---------+
| itab | data | struct Iface
+---------+---------+
| |
| |
+------+ +------+
| Itab | | data |
+------+ +------+
new
``
+---------+
| pointer | s = new([3]int)
+---------+
|
|
+---+---+---+
| 0 | 0 | 0 | [3]int
+---+---+---+
make
```
+---------+---------+---------+
| pointer | len = 1 | cap = 3 | slice = make([]int, 1, 3)
+---------+---------+---------+
|
|
+---+---+---+
| 0 | 0 | 0 | [3]int
+---+---+---+
+---------+
| pointer | map = make(map[string]int); 实际返回的是一个指针包装对象。
+---------+
|
|
..................
. .
. hashmap.c Hmap .
. .
..................
+---------+
| pointer | channel = make(chan int); 实际返回的是一个指针包装对象。
+---------+
|
|
................
. .
. chan.c Hchan .
. .
................
```
10.2 指针陷阱
- 对象内存分配会受编译参数影响。举个例子,当函数返回对象指针时,必然在堆上分配。 可如果该函数被内联,那么这个指针就不会跨栈帧使用,就有可能直接在栈上分配,以实 现代码优化目的。因此,是否阻止内联对指针输出结果有很大影响。 允许指针指向对象成员,并确保该对象是可达状态。
- 除正常指针外,指针还有 unsafe.Pointer 和 uintptr 两种形态。其中 uintptr 被 GC 当 做普通整数对象,它不能阻止所 "引用" 对象被回收。
```
type data struct {
x [1024 * 100]byte
}
func test() uintptr {
p := &data{}
return uintptr(unsafe.Pointer(p))
}
func main() {
const N = 10000
cache := new([N]uintptr)
for i := 0; i < N; i++ {
cache[i] = test()
time.Sleep(time.Millisecond)
}
}
```
输出:
``
$ go build -o test && GODEBUG="gctrace=1" ./test
gc607(1): 0+0+0 ms, 0 -> 0 MB 50 -> 45 (3070-3025) objects
gc611(1): 0+0+0 ms, 0 -> 0 MB 50 -> 45 (3090-3045) objects
gc613(1): 0+0+0 ms, 0 -> 0 MB 50 -> 45 (3100-3055) objects
- 合法的 unsafe.Pointer 被当做普通指针对待。
```
func test() unsafe.Pointer {
p := &data{}
return unsafe.Pointer(p)
}
func main() {
const N = 10000
cache := new([N]unsafe.Pointer)
for i := 0; i < N; i++ {
cache[i] = test()
time.Sleep(time.Millisecond)
}
}
```
输出:
``
$ go build -o test && GODEBUG="gctrace=1" ./test
gc12(1): 0+0+0 ms, 199 -> 199 MB 2088 -> 2088 (2095-7) objects
gc13(1): 0+0+0 ms, 399 -> 399 MB 4136 -> 4136 (4143-7) objects
gc14(1): 0+0+0 ms, 799 -> 799 MB 8232 -> 8232 (8239-7) objects
- 指向对象成员的 unsafe.Pointer,同样能确保对象不被回收。
```
type data struct {
x [1024 * 100]byte
y int
}
func test() unsafe.Pointer {
d := data{}
return unsafe.Pointer(&d.y)
}
func main() {
const N = 10000
cache := new([N]unsafe.Pointer)
for i := 0; i < N; i++ {
cache[i] = test()
time.Sleep(time.Millisecond)
}
}
```
输出:
``
$ go build -o test && GODEBUG="gctrace=1" ./test
gc12(1): 0+0+0 ms, 207 -> 207 MB 2088 -> 2088 (2095-7) objects
gc13(1): 1+0+0 ms, 415 -> 415 MB 4136 -> 4136 (4143-7) objects
gc14(1): 3+1+0 ms, 831 -> 831 MB 8232 -> 8232 (8239-7) objects
- 由于可以用 unsafe.Pointer、uintptr 创建 "dangling pointer" 等非法指针,所以在使用时需要特别小心。
- 另外,cgo C.malloc 等函数所返回指针,与 GC 无关。指针构成的 "循环引用" 加上 runtime.SetFinalizer 会导致内存泄露。
```
type Data struct {
d [1024 100]byte
o Data
}
func test() {
var a, b Data
a.o = &b
b.o = &a
runtime.SetFinalizer(&a, func(d Data) { fmt.Printf("a %p final.\n", d) })
runtime.SetFinalizer(&b, func(d Data) { fmt.Printf("b %p final.\n", d) })
}
func main() {
for {
test()
time.Sleep(time.Millisecond)
}
}
```
输出:
``
$ go build -gcflags "-N -l" && GODEBUG="gctrace=1" ./test
gc11(1): 2+0+0 ms, 104 -> 104 MB 1127 -> 1127 (1180-53) objects
gc12(1): 4+0+0 ms, 208 -> 208 MB 2151 -> 2151 (2226-75) objects
gc13(1): 8+0+1 ms, 416 -> 416 MB 4198 -> 4198 (4307-109) objects
- 垃圾回收器能正确处理 "指针循环引用",但无法确定 Finalizer 依赖次序,也就无法调用Finalizer 函数,这会导致目标对象无法变成不可达状态,其所占用内存无法被回收。
10.3 cgo
- 通过 cgo,可在 Go 和 C/C++ 代码间相互调用。受 CGO\_ENABLED 参数限制。
```
package main
/
#include <stdio.h>
#include <stdlib.h>
void hello() {
printf("Hello, World!\n");
}
/
import "C"
func main() {
C.hello()
}
```
- 调试 cgo 代码是件很麻烦的事,建议单独保存到 .c文件中。这样可以将其当做独立的 C程序进行调试。
test.h
```
#ifndef __TEST_H__
#define __TEST_H__
void hello();
#endif
```
test.c
```
#include <stdio.h>
#include "test.h"
void hello() {
printf("Hello, World!\n");
}
#ifdef __TEST__ // 避免和 Go bootstrap main 冲突。
int main(int argc, char *argv[]) {
hello();
return 0;
}
#endif
```
main.go
``
package main
/
#include "test.h"
/
import "C"
func main() {
C.hello()
}
编译和调试 C,只需在命令⾏行提供宏定义即可。 $ gcc -g -DTEST -o test test.c
- 由于 cgo 仅扫描当前目录,如果需要包含其他 C 项目,可在当前目录新建一个 C文件,
- 然后用 #include 指令将所需的 .h、.c 都包含进来,记得在 CFLAGS 中使用 "-I" 参数指定原路径。某些时候,可能还需指定 "-std" 参数。
10.3.1 Flags
- 可使用 #cgo 命令定义 CFLAGS、LDFLAGS 等参数,自动合并多个设置。
``
/
#cgo CFLAGS: -g
#cgo CFLAGS: -I./lib -D__VER__=1
#cgo LDFLAGS: -lpthread
#include "test.h"
/
import "C"
- 可设置 GOOS、GOARCH 编译条件,空格表⽰示 OR,逗号 AND,感叹号 NOT。
``
#cgo windows,386 CFLAGS: -I./lib -D__VER__=1
10.3.2 DataType
- 数据类型对应关系。 C cgo sizeof --------------------+--------------------+-------------------------------------------- char C.char 1 signed char C.schar 1 unsigned char C.uchar 1 short C.short 2 unsigned short C.ushort 2 int C.int 4 unsigned int C.uint 4 long C.long 4 或 8 unsigned long C.ulong 4 或 8 long long C.longlong 8 unsinged long long C.ulonglong 8 float C.float 4 double C.double 8 void unsafe.Pointer char *C.char size_t C.size_t NULL nil
- 可将 cgo 类型转换为标准 Go 类型。
```
/
int add(int x, int y) {
return x + y;
}
/
import "C"
func main() {
var x C.int = C.add(1, 2)
var y int = int(x)
fmt.Println(x, y)
}
```
10.3.3 String
- 字符串转换函数。
```
/
#include <stdio.h>
#include <stdlib.h>
void test(char s) {
printf("%s\n", s);
}
char cstr() {
return "abcde";
}
/
import "C"
func main() {
s := "Hello, World!"
cs := C.CString(s) // 该函数在 C heap 分配内存,需要调⽤用 free 释放。
defer C.free(unsafe.Pointer(cs)) // #include <stdlib.h>
C.test(cs)
cs = C.cstr()
fmt.Println(C.GoString(cs))
fmt.Println(C.GoStringN(cs, 2))
fmt.Println(C.GoBytes(unsafe.Pointer(cs), 2))
}
```
输出:
``
Hello, World!
abcde
ab
[97 98]
- 用 C.malloc/free 分配 C heap 内存。
```
/
#include <stdlib.h>
/
import "C"
func main() {
m := unsafe.Pointer(C.malloc(4 8))
defer C.free(m) // 注释释放内存。
p := ([4]int)(m) // 转换为数组指针。
for i := 0; i < 4; i++ {
p[i] = i + 100
}
fmt.Println(p)
}
```
输出:
``
&[100 101 102 103]
9.3.4 Struct/Enum/Union
- 对 struct、enum 支持良好,union 会被转换成字节数组。如果没使用 typedef 定义,那么必须添加 struct_、enum_、union\_ 前缀。
struct
````
/*
#include <stdlib.h>
struct Data {
int x;
};
typedef struct {
int x;
} DataType;
struct Data testData() {
return malloc(sizeof(struct Data));
}
DataType testDataType() {
return malloc(sizeof(DataType));
}
*/
import "C"
func main() {
var d *C.struct_Data = C.testData()
defer C.free(unsafe.Pointer(d))
var dt *C.DataType = C.testDataType()
defer C.free(unsafe.Pointer(dt))
d.x = 100
dt.x = 200
fmt.Printf("%#v\n", d)
fmt.Printf("%#v\n", dt)
}
输出:
``go```
&main._Ctype_struct_Data{x:100}
&main._Ctype_DataType{x:200}
enum
```
/
enum Color { BLACK = 10, RED, BLUE };
typedef enum { INSERT = 3, DELETE } Mode;
/
import "C"
func main() {
var c C.enum_Color = C.RED
var x uint32 = c
fmt.Println(c, x)
var m C.Mode = C.INSERT
fmt.Println(m)
}
```
union
```
/
#include <stdlib.h>
union Data {
char x;
int y;
};
union Data test() {
union Data p = malloc(sizeof(union Data));
p->x = 100;
return p;
}
/
import "C"
func main() {
var d *C.union_Data = C.test()
defer C.free(unsafe.Pointer(d))
fmt.Println(d)
}
```
输出:
``
&[100 0 0 0]
````
### 9.3.5 Export
* 导出 Go 函数给 C调用,须使用 "//export" 标记。建议在独立头文件中声明函数原型,避免 "duplicate symbol" 错误。
main.go
```go
package main
import "fmt"
/
#include "test.h"
/
import "C"
//export hello
func hello() {
fmt.Println("Hello, World!\n")
}
func main() {
C.test()
}
````
test.h
```
#ifndef __TEST_H__
#define __TEST_H__
extern void hello();
void test();
#endif
```
test.c
``
#include <stdio.h>
#include "test.h"
void test() {
hello();
}
10.3.6 Shared Library
- 在 cgo 中使用 C 共享库。
test.h
``
#ifndef __TEST_HEAD__
#define __TEST_HEAD__
int sum(int x, int y);
#endif
test.c
``
#include <stdio.h>
#include <stdlib.h>
#include "test.h"
int sum(int x, int y)
{
return x + y + 100;
}
编译成 .so 或 .dylib。
``
$ gcc -c -fPIC -o test.o test.c
$ gcc -dynamiclib -o libtest.dylib test.o
将共享库和头文件拷贝到 Go 项目目录。
main.go
``
package main
/
#cgo CFLAGS: -I.
#cgo LDFLAGS: -L. -ltest
#include "test.h"
/
import "C"
func main() {
println(C.sum(10, 20))
}
输出:
``
$ go build -o test && ./test
130
- 编译成功后可用 ldd 或 otool 查看动态库使用状态。 静态库使用方法类似。
10.4 Reflect
- 没有运行期类型对象,实例也没有附加字段用来表明身份。只有转换成接口时,才会在其itab 内部存储与该类型有关的信息,Reflect 所有操作都依赖于此。
10.4.1 Type
- 以 struct 为例,可获取其全部成员字段信息,包括非导出和匿名字段。
```
type User struct {
Username string
}
type Admin struct {
User
title string
}
func main() {
var u Admin
t := reflect.TypeOf(u)
for i, n := 0, t.NumField(); i < n; i++ {
f := t.Field(i)
fmt.Println(f.Name, f.Type)
}
}
```
输出:
``
User main.User // 可进一步递归。
title string
- 如果是指针,应该先使用 Elem方法获取目标类型,指针本身是没有字段成员的。
``
func main() {
u := new(Admin)
t := reflect.TypeOf(u)
if t.Kind() == reflect.Ptr {
t = t.Elem()
}
for i, n := 0, t.NumField(); i < n; i++ {
f := t.Field(i)
fmt.Println(f.Name, f.Type)
}
}
- 同样,value-interface 和 pointer-interface 也会导致方法集存在差异。
```
type User struct {
}
type Admin struct {
User
}
func (*User) ToString() {}
func (Admin) test() {}
func main() {
var u Admin
methods := func(t reflect.Type) {
for i, n := 0, t.NumMethod(); i < n; i++ {
m := t.Method(i)
fmt.Println(m.Name)
}
}
fmt.Println("--- value interface ---")
methods(reflect.TypeOf(u))
fmt.Println("--- pointer interface ---")
methods(reflect.TypeOf(&u))
}
```
输出:
``
--- value interface ---
test
--- pointer interface ---
ToString
test
- 可直接用名称或序号访问字段,包括用多级序号访问嵌入字段成员。
```
type User struct {
Username string
age int
}
type Admin struct {
User
title string
}
func main() {
var u Admin
t := reflect.TypeOf(u)
f, _ := t.FieldByName("title")
fmt.Println(f.Name)
f, _ = t.FieldByName("User") // 访问嵌⼊入字段。
fmt.Println(f.Name)
f, _ = t.FieldByName("Username") // 直接访问嵌⼊入字段成员,会⾃自动深度查找。
fmt.Println(f.Name)
f = t.FieldByIndex([]int{0, 1}) // Admin[0] -> User[1] -> age
fmt.Println(f.Name)
}
```
输出:
``
title
User
Username
age
- 字段标签可实现简单元数据编程,比如标记 ORM Model 属性。
``
type User struct {
Name string
Age int
}
func main() {
var u User
t := reflect.TypeOf(u)
f, _ := t.FieldByName("Name")
fmt.Println(f.Tag)
fmt.Println(f.Tag.Get("field"))
fmt.Println(f.Tag.Get("type"))
}
```
输出:
``
field:"username" type:"nvarchar(20)"
username
nvarchar(20)
- 可从基本类型获取所对应复合类型。
```
var (
Int = reflect.TypeOf(0)
String = reflect.TypeOf("")
)
func main() {
c := reflect.ChanOf(reflect.SendDir, String)
fmt.Println(c)
m := reflect.MapOf(String, Int)
fmt.Println(m)
s := reflect.SliceOf(Int)
fmt.Println(s)
t := struct{ Name string }{}
p := reflect.PtrTo(reflect.TypeOf(t))
fmt.Println(p)
}
```
输出:
``
chan<- string
map[string]int
[]int
*struct { Name string }
与之对应方法 Elem 可返回复合类型的基类型。
``
func main() {
t := reflect.TypeOf(make(chan int)).Elem()
fmt.Println(t)
}
- 方法 Implements 判断是否实现了某个具体接口,AssignableTo、ConvertibleTo用于赋值和转换判断。
```
type Data struct {
}
func (*Data) String() string {
return ""
}
func main() {
var d *Data
t := reflect.TypeOf(d)
// 没法直接获取接⼝口类型,好在接口本身是个 struct,创建
// 一个空指针对象,这样传递给 TypeOf 转换成 interface{}
// 时就有类型信息了。。
it := reflect.TypeOf((*fmt.Stringer)(nil)).Elem()
// 为啥不是 t.Implements(fmt.Stringer),完全可以由编译器生成。
fmt.Println(t.Implements(it))
}
```
- 某些时候,获取对齐信息对于内存自动分析是很有用的。
```
type Data struct {
b byte
x int32
}
func main() {
var d Data
t := reflect.TypeOf(d)
fmt.Println(t.Size(), t.Align()) // sizeof,以及最宽字段的对齐模数。
f, _ := t.FieldByName("b")
fmt.Println(f.Type.FieldAlign()) // 字段对齐。
}
```
输出:
``
8 4
1
10.4.2 Value
- Value 和 Type 使用方法类似,包括使用 Elem 获取指针目标对象。
```
type User struct {
Username string
age int
}
type Admin struct {
User
title string
}
func main() {
u := &Admin{User{"Jack", 23}, "NT"}
v := reflect.ValueOf(u).Elem()
fmt.Println(v.FieldByName("title").String()) // 用转换方法获取字段值
fmt.Println(v.FieldByName("age").Int()) // 直接访问嵌入字段成员
fmt.Println(v.FieldByIndex([]int{0, 1}).Int()) // 用多级序号访问嵌入字段成员
}
```
输出:
``
NT
23
23
- 除具体的 Int、String 等转换方法,还可返回 interface{}。只是非导出字段无法使用,需用 CanInterface 判断一下。
```
type User struct {
Username string
age int
}
func main() {
u := User{"Jack", 23}
v := reflect.ValueOf(u)
fmt.Println(v.FieldByName("Username").Interface())
fmt.Println(v.FieldByName("age").Interface())
}
```
输出:
``
Jack
panic: reflect.Value.Interface: cannot return value obtained from unexported field or method
- 当然,转换成具体类型不会引发 panic。
```
func main() {
u := User{"Jack", 23}
v := reflect.ValueOf(u)
f := v.FieldByName("age")
if f.CanInterface() {
fmt.Println(f.Interface())
} else {
fmt.Println(f.Int())
}
}
```
- 除 struct,其他复合类型 array、slice、map 取值示例。
```
func main() {
v := reflect.ValueOf([]int{1, 2, 3})
for i, n := 0, v.Len(); i < n; i++ {
fmt.Println(v.Index(i).Int())
}
fmt.Println("---------------------------")
v = reflect.ValueOf(map[string]int{"a": 1, "b": 2})
for _, k := range v.MapKeys() {
fmt.Println(k.String(), v.MapIndex(k).Int())
}
}
```
输出:
``
1
2
3
---------------------------
a 1
b 2
- 需要注意,Value 某些方法没有遵循 "comma ok" 模式,而是返回 ZeroValue,因此需要用 IsValid 判断一下是否可用。
```
func (v Value) FieldByName(name string) Value {
v.mustBe(Struct)
if f, ok := v.typ.FieldByName(name); ok {
return v.FieldByIndex(f.Index)
}
return Value{}
}
type User struct {
Username string
age int
}
func main() {
u := User{}
v := reflect.ValueOf(u)
f := v.FieldByName("a")
fmt.Println(f.Kind(), f.IsValid())
}
```
输出:
``
invalid false
- 另外,接口是否为 nil,需要 tab 和 data 都为空。可使用 IsNil 方法判断 data 值。
```
func main() {
var p *int
var x interface{} = p
fmt.Println(x == nil)
v := reflect.ValueOf(p)
fmt.Println(v.Kind(), v.IsNil())
}
```
输出:
``
false
ptr true
- 将对象转换为接口,会发生复制行为。该复制品只读,无法被修改。所以要通过接口改变目标对象状态,必须是 pointer-interface。
- 就算是指针,我们依然没法将这个存储在 data 的指针指向其他对象,只能透过它修改目标对象。目标对象并没有被复制,被复制的只是指针。
```
type User struct {
Username string
age int
}
func main() {
u := User{"Jack", 23}
v := reflect.ValueOf(u)
p := reflect.ValueOf(&u)
fmt.Println(v.CanSet(), v.FieldByName("Username").CanSet())
fmt.Println(p.CanSet(), p.Elem().FieldByName("Username").CanSet())
}
```
输出:
``
false false
false true
- 非导出字段无法直接修改,可改用指针操作。
```
type User struct {
Username string
age int
}
func main() {
u := User{"Jack", 23}
p := reflect.ValueOf(&u).Elem()
p.FieldByName("Username").SetString("Tom")
f := p.FieldByName("age")
fmt.Println(f.CanSet())
// 判断是否能获取地址。
if f.CanAddr() {
age := (int)(unsafe.Pointer(f.UnsafeAddr()))
// age := (int)(unsafe.Pointer(f.Addr().Pointer())) // 等同
*age = 88
}
// 注意 p 是 Value 类型,需要还原成接口才能转型。
fmt.Println(u, p.Interface().(User))
}
```
输出:
``
false
{Tom 88} {Tom 88}
- 复合类型修改示例。
```
func main() {
s := make([]int, 0, 10)
v := reflect.ValueOf(&s).Elem()
v.SetLen(2)
v.Index(0).SetInt(100)
v.Index(1).SetInt(200)
fmt.Println(v.Interface(), s)
v2 := reflect.Append(v, reflect.ValueOf(300))
v2 = reflect.AppendSlice(v2, reflect.ValueOf([]int{400, 500}))
fmt.Println(v2.Interface())
fmt.Println("----------------------")
m := map[string]int{"a": 1}
v = reflect.ValueOf(&m).Elem()
v.SetMapIndex(reflect.ValueOf("a"), reflect.ValueOf(100)) // update
v.SetMapIndex(reflect.ValueOf("b"), reflect.ValueOf(200)) // add
fmt.Println(v.Interface(), m)
}
```
输出:
``
[100 200] [100 200]
[100 200 300 400 500]
----------------------
map[a:100 b:200] map[a:100 b:200]
9.4.3 Method
- 可获取方法参数、返回值类型等信息。
```
type Data struct {
}
func (*Data) Test(x, y int) (int, int) {
return x + 100, y + 100
}
func (*Data) Sum(s string, x ...int) string {
c := 0
for _, n := range x {
c += n
}
return fmt.Sprintf(s, c)
}
func info(m reflect.Method) {
t := m.Type
fmt.Println(m.Name)
for i, n := 0, t.NumIn(); i < n; i++ {
fmt.Printf(" in[%d] %v\n", i, t.In(i))
}
for i, n := 0, t.NumOut(); i < n; i++ {
fmt.Printf(" out[%d] %v\n", i, t.Out(i))
}
}
func main() {
d := new(Data)
t := reflect.TypeOf(d)
test, _ := t.MethodByName("Test")
info(test)
sum, _ := t.MethodByName("Sum")
info(sum)
}
```
输出:
``
Test
in[0] main.Data // receiver
in[1] int
in[2] int
out[0] int
out[1] int
Sum
in[0] main.Data
in[1] string
in[2] []int
out[0] string
- 动态调用方法很简单,按 In 列表准备好所需参数即可 (不包括 receiver)。
```
func main() {
d := new(Data)
v := reflect.ValueOf(d)
exec := func(name string, in []reflect.Value) {
m := v.MethodByName(name)
out := m.Call(in)
for _, v := range out {
fmt.Println(v.Interface())
}
}
exec("Test", []reflect.Value{
reflect.ValueOf(1),
reflect.ValueOf(2),
})
fmt.Println("-----------------------")
exec("Sum", []reflect.Value{
reflect.ValueOf("result = %d"),
reflect.ValueOf(1),
reflect.ValueOf(2),
})
}
```
输出:
``
101
102
-----------------------
result = 3
- 如改用 CallSlice,只需将变参打包成 slice 即可。
```
func main() {
d := new(Data)
v := reflect.ValueOf(d)
m := v.MethodByName("Sum")
in := []reflect.Value{
reflect.ValueOf("result = %d"),
reflect.ValueOf([]int{1, 2}), // 将变参打包成 slice。
}
out := m.CallSlice(in)
for _, v := range out {
fmt.Println(v.Interface())
}
}
```
- 非导出方法无法调用,甚至无法透过指针操作,因为接口类型信息中没有该方法地址。
10.4.4 Make
- 利用 Make、New 等函数,可实现近似泛型操作。
```
var (
Int = reflect.TypeOf(0)
String = reflect.TypeOf("")
)
func Make(T reflect.Type, fptr interface{}) {
// 实际创建 slice 的包装函数。
swap := func(in []reflect.Value) []reflect.Value {
// --- 省略算法内容 --- //
// 返回和类型匹配的 slice 对象。
return []reflect.Value{
reflect.MakeSlice(
reflect.SliceOf(T), // slice type
int(in[0].Int()), // len
int(in[1].Int()) // cap
),
}
}
// 传入的是函数变量指针,因为我们要将变量指向 swap 函数。
fn := reflect.ValueOf(fptr).Elem()
// 获取函数指针类型,生成所需 swap function value。
v := reflect.MakeFunc(fn.Type(), swap)
// 修改函数指针实际指向,也就是 swap。
fn.Set(v)
}
func main() {
var makeints func(int, int) []int
var makestrings func(int, int) []string
// 用相同算法,生成不同类型创建函数。
Make(Int, &makeints)
Make(String, &makestrings)
// 按实际类型使用。
x := makeints(5, 10)
fmt.Printf("%#v\n", x)
s := makestrings(3, 10)
fmt.Printf("%#v\n", s)
}
```
输出:
``
[]int{0, 0, 0, 0, 0}
[]string{"", "", ""}
- 原理并不复杂。
1. 核心是提供一个 swap 函数,其中利用 reflect.MakeSlice生成最终 slice 对象,因此需要传入 element type、len、cap 参数。